正在加载图片...
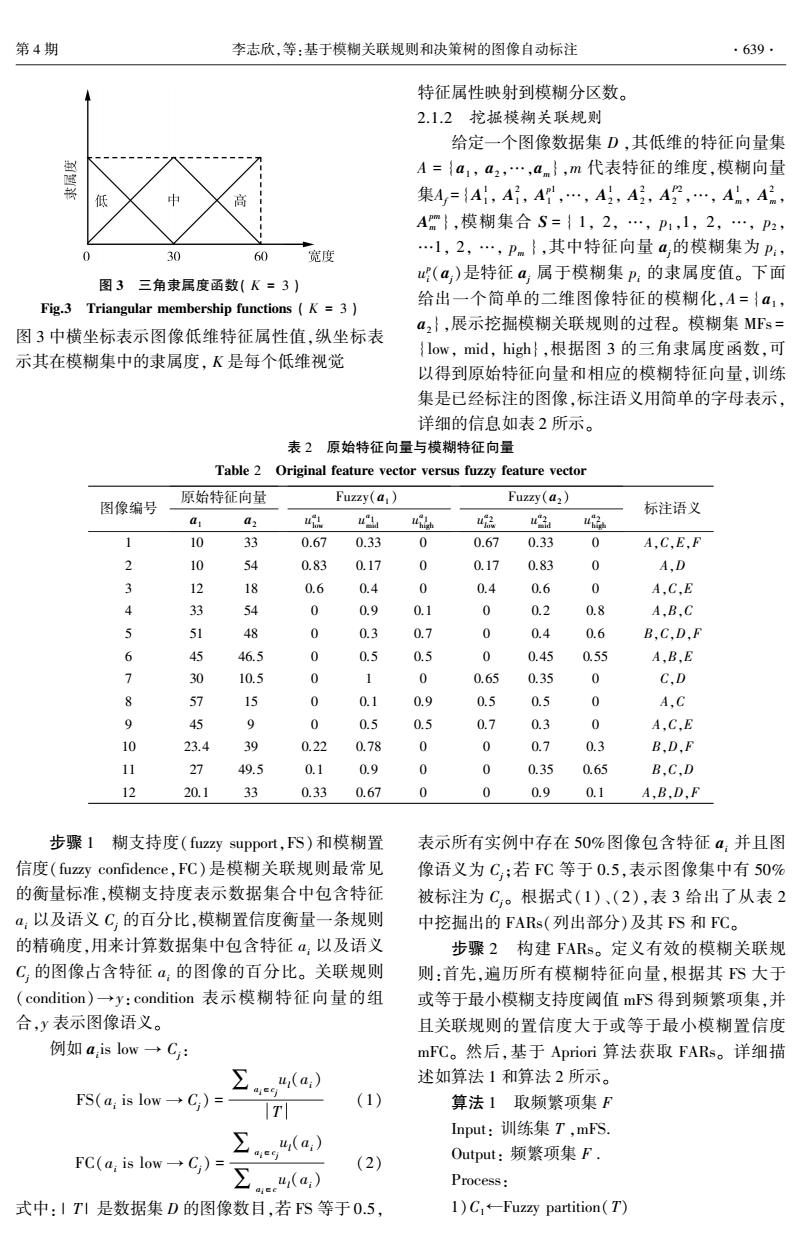
第4期 李志欣,等:基于模糊关联规则和决策树的图像自动标注 .639· 特征属性映射到模糊分区数。 2.1.2挖掘模糊关联规则 给定一个图像数据集D,其低维的特征向量集 赵 A={a,a2,…,an},m代表特征的维度,模糊向量 低 中 集A,={A1,A,A,…,A,A号,A,…,A,A2 Am},模糊集合S={1,2,…,P1,1,2,…,P2, 0 30 60 宽度 …l,2,…,pm},其中特征向量a的模糊集为p:, (a)是特征a属于模糊集P:的隶属度值。下面 图3三角隶属度函数(K=3) Fig.3 Triangular membership functions (K 3 给出一个简单的二维图像特征的模糊化,A={a1, a2},展示挖掘模糊关联规则的过程。模糊集MFs= 图3中横坐标表示图像低维特征属性值,纵坐标表 {low,mid,high},根据图3的三角隶属度函数,可 示其在模糊集中的隶属度,K是每个低维视觉 以得到原始特征向量和相应的模糊特征向量,训练 集是已经标注的图像,标注语义用简单的字母表示, 详细的信息如表2所示。 表2原始特征向量与模糊特征向量 Table 2 Original feature vector versus fuzzy feature vector 原始特征向量 图像编号 Fuzzy(a,) Fuzy(a2) 标注语义 a a2 t u 4品 ui u峰 1 10 33 0.67 0.33 0 0.67 0.33 0 A.C.E.F 2 10 54 0.83 0.17 0 0.17 0.83 0 A.D 3 12 18 0.6 0.4 0 0.4 0.6 0 A,C,E 4 3 54 0 0.9 0.1 0 0.2 0.8 A,B,C 5 51 48 0 0.3 0.7 0 0.4 0.6 B.C.D,F 6 45 46.5 0 0.5 0.5 0 0.45 0.55 A,B,E 7 30 10.5 1 0 0.65 0.35 0 C.D 8 57 15 0 0.1 0.9 0.5 0.5 0 A,C 9 45 9 0 0.5 0.5 0.7 0.3 0 A.C,E 10 23.4 西 0.22 0.78 0 0 0.7 0.3 B.D,F 11 27 49.5 0.1 0.9 0 0 0.35 0.65 B.C,D 12 20.1 33 0.33 0.67 0 0 0.9 0.1 A,B,D,F 步骤1糊支持度(fuzzy support,FS)和模糊置 表示所有实例中存在50%图像包含特征4,并且图 信度(fuzzy confidence,FC)是模糊关联规则最常见 像语义为C,:若FC等于0.5,表示图像集中有50% 的衡量标准,模糊支持度表示数据集合中包含特征 被标注为C。根据式(1)、(2),表3给出了从表2 a:以及语义C的百分比,模糊置信度衡量一条规则 中挖掘出的FARs(列出部分)及其FS和FC。 的精确度,用来计算数据集中包含特征a:以及语义 步骤2构建FARs。定义有效的模糊关联规 C:的图像占含特征α:的图像的百分比。关联规则 则:首先,遍历所有模糊特征向量,根据其FS大于 (condition)→y:condition表示模糊特征向量的组 或等于最小模糊支持度阈值mS得到频繁项集,并 合,y表示图像语义。 且关联规则的置信度大于或等于最小模糊置信度 例如a,is low→C: mFC。然后,基于Apriori算法获取FARs。详细描 u(a:)) 述如算法1和算法2所示。 FS(a:is low→C)= tl (1) 算法1取频繁项集F Input:训练集T,mFS. u(a:) FC(a:is low→C)= (2) Output:频繁项集F. Process: 式中:1T1是数据集D的图像数目,若FS等于0.5, 1)C+-Fuzzy partition(T)图 3 三角隶属度函数( K = 3 ) Fig.3 Triangular membership functions ( K = 3 ) 图 3 中横坐标表示图像低维特征属性值,纵坐标表 示其在模糊集中的隶属度, K 是每个低维视觉 特征属性映射到模糊分区数。 2.1.2 挖掘模糊关联规则 给定一个图像数据集 D ,其低维的特征向量集 A = {a1 , a2 ,…,am },m 代表特征的维度,模糊向量 集Af = {A 1 1 , A 2 1 , A p1 1 ,…, A 1 2 , A 2 2 , A P2 2 ,…, A 1 m , A 2 m , A pm m },模糊集合 S = { 1, 2, …, p1 ,1, 2, …, p2 , …1, 2, …, pm },其中特征向量 aj的模糊集为 pi, u p i(aj)是特征 aj 属于模糊集 pi 的隶属度值。 下面 给出一个简单的二维图像特征的模糊化,A = { a1 , a2 },展示挖掘模糊关联规则的过程。 模糊集 MFs = {low, mid, high},根据图 3 的三角隶属度函数,可 以得到原始特征向量和相应的模糊特征向量,训练 集是已经标注的图像,标注语义用简单的字母表示, 详细的信息如表 2 所示。 表 2 原始特征向量与模糊特征向量 Table 2 Original feature vector versus fuzzy feature vector 图像编号 原始特征向量 a1 a2 Fuzzy(a1 ) u a 1 low u a 1 mid u a 1 high Fuzzy(a2 ) u a 2 low u a 2 mid u a 2 high 标注语义 1 10 33 0.67 0.33 0 0.67 0.33 0 A,C,E,F 2 10 54 0.83 0.17 0 0.17 0.83 0 A,D 3 12 18 0.6 0.4 0 0.4 0.6 0 A,C,E 4 33 54 0 0.9 0.1 0 0.2 0.8 A,B,C 5 51 48 0 0.3 0.7 0 0.4 0.6 B,C,D,F 6 45 46.5 0 0.5 0.5 0 0.45 0.55 A,B,E 7 30 10.5 0 1 0 0.65 0.35 0 C,D 8 57 15 0 0.1 0.9 0.5 0.5 0 A,C 9 45 9 0 0.5 0.5 0.7 0.3 0 A,C,E 10 23.4 39 0.22 0.78 0 0 0.7 0.3 B,D,F 11 27 49.5 0.1 0.9 0 0 0.35 0.65 B,C,D 12 20.1 33 0.33 0.67 0 0 0.9 0.1 A,B,D,F 步骤 1 糊支持度( fuzzy support,FS)和模糊置 信度(fuzzy confidence,FC)是模糊关联规则最常见 的衡量标准,模糊支持度表示数据集合中包含特征 ai 以及语义 Cj 的百分比,模糊置信度衡量一条规则 的精确度,用来计算数据集中包含特征 ai 以及语义 Cj 的图像占含特征 ai 的图像的百分比。 关联规则 (condition) →y:condition 表示模糊特征向量的组 合,y 表示图像语义。 例如 ai is low → Cj: FS(ai is low → Cj) = ∑ai∈cj ul(ai) T (1) FC(ai is low → Cj) = ∑ai∈cj ul(ai) ∑ai∈c ul(ai) (2) 式中: | T | 是数据集 D 的图像数目,若 FS 等于 0.5, 表示所有实例中存在 50%图像包含特征 ai 并且图 像语义为 Cj;若 FC 等于 0.5,表示图像集中有 50% 被标注为 Cj。 根据式(1)、(2),表 3 给出了从表 2 中挖掘出的 FARs(列出部分)及其 FS 和 FC。 步骤 2 构建 FARs。 定义有效的模糊关联规 则:首先,遍历所有模糊特征向量,根据其 FS 大于 或等于最小模糊支持度阈值 mFS 得到频繁项集,并 且关联规则的置信度大于或等于最小模糊置信度 mFC。 然后,基于 Apriori 算法获取 FARs。 详细描 述如算法 1 和算法 2 所示。 算法 1 取频繁项集 F Input: 训练集 T ,mFS. Output: 频繁项集 F . Process: 1)C1←Fuzzy partition(T) 第 4 期 李志欣,等:基于模糊关联规则和决策树的图像自动标注 ·639·