正在加载图片...
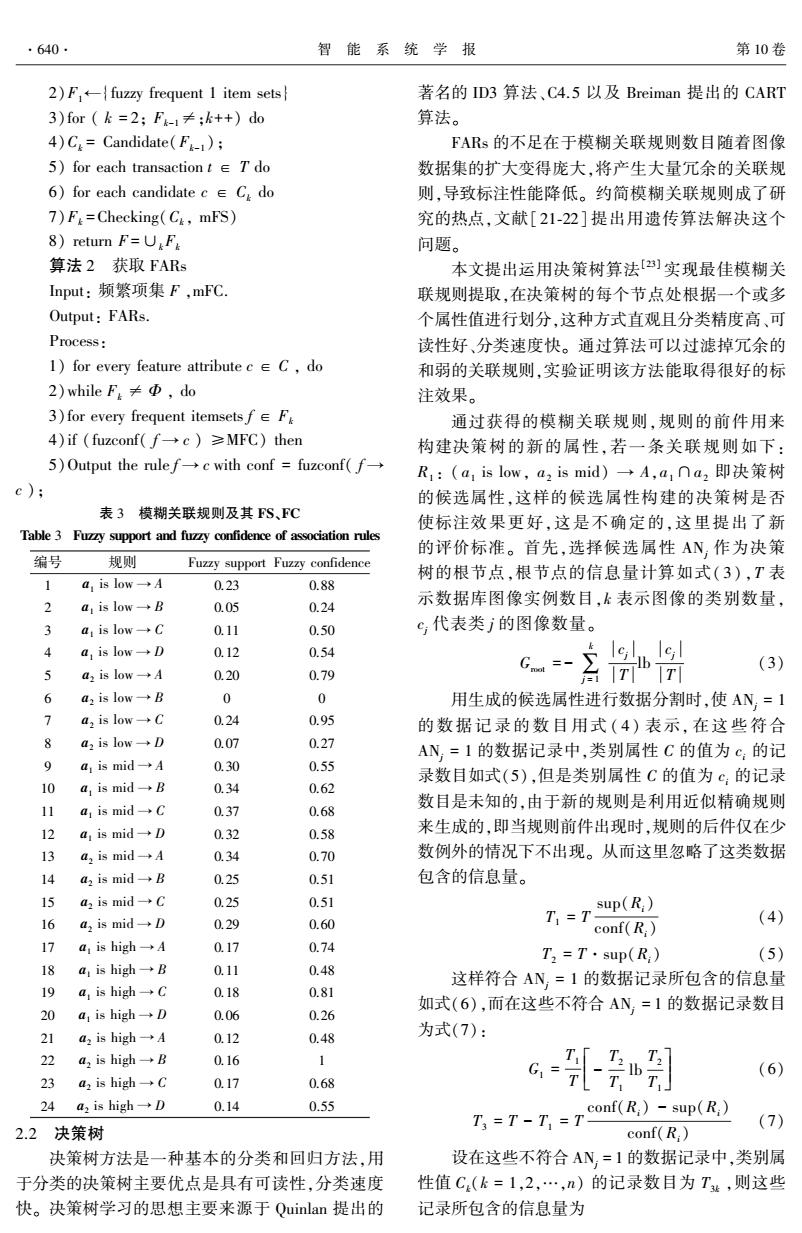
·640. 智能系统学报 第10卷 2)Ffuzzy frequent 1 item sets 著名的ID3算法、C4.5以及Breiman提出的CART 3)for(k=2;Fk-1≠;k++)do 算法。 4)Ca=Candidate(F-1); FARs的不足在于模糊关联规则数目随着图像 5)for each transaction tT do 数据集的扩大变得庞大,将产生大量冗余的关联规 6)for each candidate cC do 则,导致标注性能降低。约简模糊关联规则成了研 7)F=Checking(C,mFS) 究的热点,文献[21-22]提出用遗传算法解决这个 8)return F=UF 问题。 算法2获取FARs 本文提出运用决策树算法[]实现最佳模糊关 Input:频繁项集F,mFC. 联规则提取,在决策树的每个节点处根据一个或多 Output:FARs. 个属性值进行划分,这种方式直观且分类精度高、可 Process: 读性好、分类速度快。通过算法可以过滤掉冗余的 1)for every feature attribute cC,do 和弱的关联规则,实验证明该方法能取得很好的标 2)while F≠Φ,do 注效果。 3)for every frequent itemsets fF 通过获得的模糊关联规则,规则的前件用来 4)if(fuzconf(f→c)≥MFC)then 构建决策树的新的属性,若一条关联规则如下: 5)Output the rule f→c with conf=fuzconf(f→ R1:(a1 is low,a2 is mid)→A,a1∩a2即决策树 c); 的候选属性,这样的候选属性构建的决策树是否 表3模糊关联规则及其FS、FC 使标注效果更好,这是不确定的,这里提出了新 Table 3 Fuzzy support and fuzzy confidence of association rules 的评价标准。首先,选择候选属性AN作为决策 编号 规则 Fuzzy support Fuzzy confidence a,is low→A 树的根节点,根节点的信息量计算如式(3),T表 1 0.23 0.88 2 a is lowB 0.05 0.24 示数据库图像实例数目,k表示图像的类别数量, 3 a,is low→C 0.11 0.50 S代表类j的图像数量。 4 a is lowD 0.12 0.54 (3) 5 a2 is low→A 0.20 0.79 6名阁 6 a2 is low→B 0 0 用生成的候选属性进行数据分割时,使AN=1 7 a2 is low-C 0.24 0.95 的数据记录的数目用式(4)表示,在这些符合 8 a2 is low→+D 0.07 0.27 AN=1的数据记录中,类别属性C的值为c:的记 9 a,is mid→A 0.30 0.55 录数目如式(5),但是类别属性C的值为c:的记录 10 a,is mid→B 0.34 0.62 11 a1 is mid→C 数目是未知的,由于新的规则是利用近似精确规则 0.37 0.68 12 a,is mid→D 0.32 0.58 来生成的,即当规则前件出现时,规则的后件仅在少 13 a2 is mid→A 0.34 0.70 数例外的情况下不出现。从而这里忽略了这类数据 14 a2 is mid→B 0.25 0.51 包含的信息量。 15 a is midC 0.25 0.51 16 a2 is mid→D 0.29 0.60 T =T sup(R.) (4) conf(R:) 17 a1 is high→A 0.17 0.74 T2=T·sup(R:) (5) 18 a,is high一→B 0.11 0.48 这样符合AN,=1的数据记录所包含的信息量 19 a.is high→C 0.18 0.81 如式(6),而在这些不符合AN=1的数据记录数目 20 a1 is high→D 0.06 0.26 21 a2 is highA 0.12 0.48 为式(7): 22 a2 is high→B 0.16 1 (6) 23 a,is high→C 0.17 0.68 24a2 is high→D 0.14 0.55 (7) 2.2决策树 T3=T-T;=7conf(R:)-sup(R) conf(R) 决策树方法是一种基本的分类和回归方法,用 设在这些不符合AN,=1的数据记录中,类别属 于分类的决策树主要优点是具有可读性,分类速度 性值C(k=1,2,…,n)的记录数目为T4,则这些 快。决策树学习的思想主要来源于Quinlan提出的 记录所包含的信息量为2)F1←{fuzzy frequent 1 item sets} 3)for ( k = 2; Fk-1≠;k++) do 4)Ck = Candidate(Fk-1 ); 5) for each transaction t ∈ T do 6) for each candidate c ∈ Ck do 7)Fk =Checking(Ck, mFS) 8) return F =∪kFk 算法 2 获取 FARs Input: 频繁项集 F ,mFC. Output: FARs. Process: 1) for every feature attribute c ∈ C , do 2)while Fk ≠ Φ , do 3)for every frequent itemsets f ∈ Fk 4)if (fuzconf( f → c ) ≥MFC) then 5)Output the rule f → c with conf = fuzconf( f → c ); 表 3 模糊关联规则及其 FS、FC Table 3 Fuzzy support and fuzzy confidence of association rules 编号 规则 Fuzzy support Fuzzy confidence 1 a1 is low → A 0.23 0.88 2 a1 is low → B 0.05 0.24 3 a1 is low → C 0.11 0.50 4 a1 is low → D 0.12 0.54 5 a2 is low → A 0.20 0.79 6 a2 is low → B 0 0 7 a2 is low → C 0.24 0.95 8 a2 is low → D 0.07 0.27 9 a1 is mid → A 0.30 0.55 10 a1 is mid → B 0.34 0.62 11 a1 is mid → C 0.37 0.68 12 a1 is mid → D 0.32 0.58 13 a2 is mid → A 0.34 0.70 14 a2 is mid → B 0.25 0.51 15 a2 is mid → C 0.25 0.51 16 a2 is mid → D 0.29 0.60 17 a1 is high → A 0.17 0.74 18 a1 is high → B 0.11 0.48 19 a1 is high → C 0.18 0.81 20 a1 is high → D 0.06 0.26 21 a2 is high → A 0.12 0.48 22 a2 is high → B 0.16 1 23 a2 is high → C 0.17 0.68 24 a2 is high → D 0.14 0.55 2.2 决策树 决策树方法是一种基本的分类和回归方法,用 于分类的决策树主要优点是具有可读性,分类速度 快。 决策树学习的思想主要来源于 Quinlan 提出的 著名的 ID3 算法、C4.5 以及 Breiman 提出的 CART 算法。 FARs 的不足在于模糊关联规则数目随着图像 数据集的扩大变得庞大,将产生大量冗余的关联规 则,导致标注性能降低。 约简模糊关联规则成了研 究的热点,文献[21⁃22] 提出用遗传算法解决这个 问题。 本文提出运用决策树算法[23] 实现最佳模糊关 联规则提取,在决策树的每个节点处根据一个或多 个属性值进行划分,这种方式直观且分类精度高、可 读性好、分类速度快。 通过算法可以过滤掉冗余的 和弱的关联规则,实验证明该方法能取得很好的标 注效果。 通过获得的模糊关联规则,规则的前件用来 构建决策树的新的属性,若一条关联规则如下: R1 : ( a1 is low, a2 is mid) → A,a1∩a2 即决策树 的候选属性,这样的候选属性构建的决策树是否 使标注效果更好,这是不确定的,这里提出了新 的评价标准。 首先,选择候选属性 ANj 作为决策 树的根节点,根节点的信息量计算如式( 3) ,T 表 示数据库图像实例数目,k 表示图像的类别数量, cj 代表类 j 的图像数量。 Groot = - ∑ k j = 1 cj T lb cj T (3) 用生成的候选属性进行数据分割时,使 ANj = 1 的数 据 记 录 的 数 目 用 式 ( 4) 表 示, 在 这 些 符 合 ANj = 1 的数据记录中,类别属性 C 的值为 ci 的记 录数目如式(5),但是类别属性 C 的值为 ci 的记录 数目是未知的,由于新的规则是利用近似精确规则 来生成的,即当规则前件出现时,规则的后件仅在少 数例外的情况下不出现。 从而这里忽略了这类数据 包含的信息量。 T1 = T sup(Ri) conf(Ri) (4) T2 = T·sup(Ri) (5) 这样符合 ANj = 1 的数据记录所包含的信息量 如式(6),而在这些不符合 ANj = 1 的数据记录数目 为式(7): G1 = T1 T - T2 T1 lb T2 T1 é ë ê ê ù û ú ú (6) T3 = T - T1 = T conf(Ri) - sup(Ri) conf(Ri) (7) 设在这些不符合 ANj = 1 的数据记录中,类别属 性值 Ck(k = 1,2,…,n) 的记录数目为 T3k ,则这些 记录所包含的信息量为 ·640· 智 能 系 统 学 报 第 10 卷