正在加载图片...
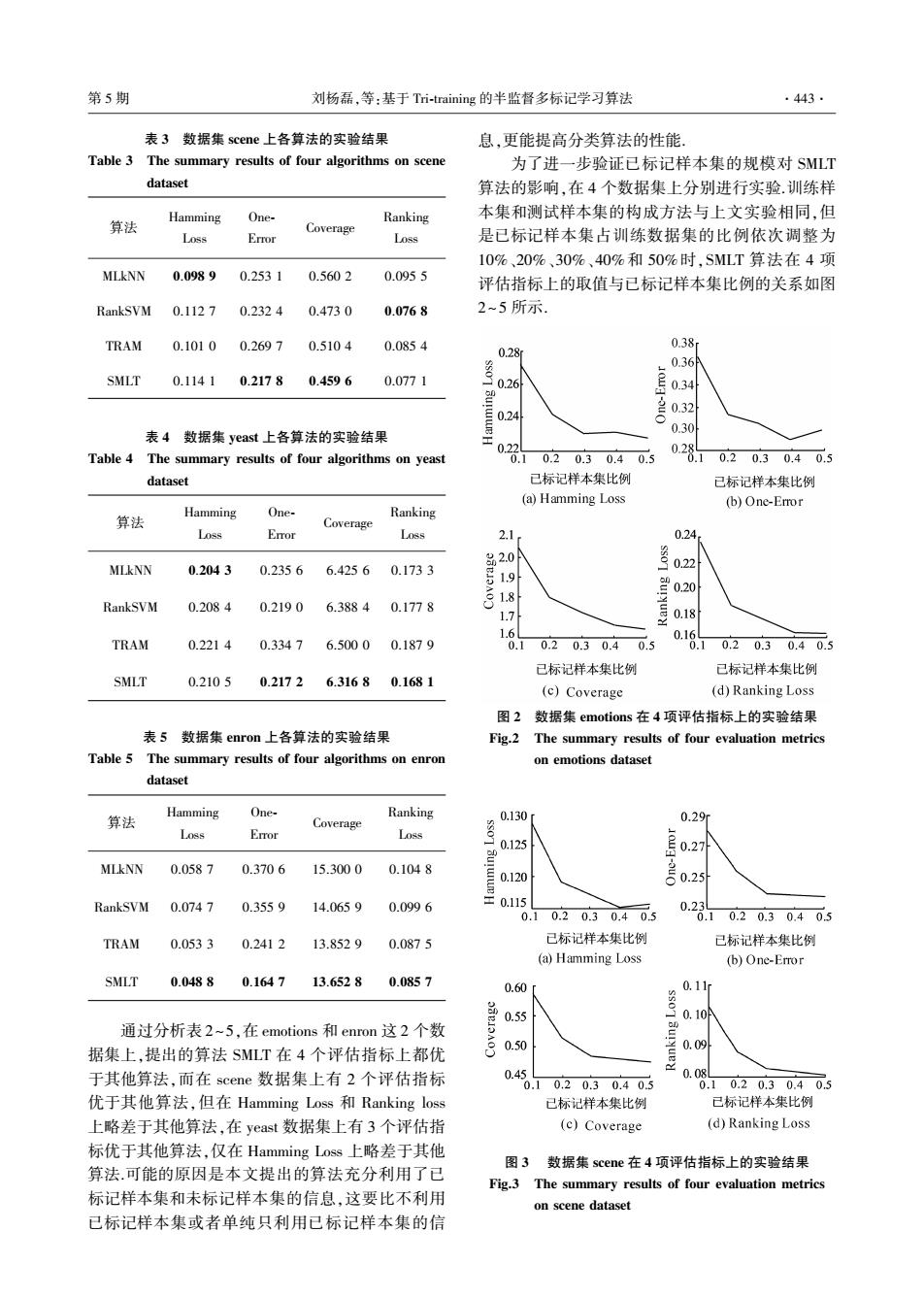
第5期 刘杨磊,等:基于Ti-training的半监督多标记学习算法 .443. 表3数据集scene上各算法的实验结果 息,更能提高分类算法的性能。 Table 3 The summary results of four algorithms on scene 为了进一步验证已标记样本集的规模对SMLT dataset 算法的影响,在4个数据集上分别进行实验.训练样 Hamming One- Ranking 本集和测试样本集的构成方法与上文实验相同,但 算法 Coverage Loss Error Loss 是已标记样本集占训练数据集的比例依次调整为 10%、20%、30%、40%和50%时,SMLT算法在4项 MLkNN 0.0989 0.2531 0.5602 0.0955 评估指标上的取值与已标记样本集比例的关系如图 RankSVM 0.1127 0.2324 0.4730 0.0768 2~5所示 TRAM 0.1010 0.2697 0.5104 0.0854 0.38 0.28 0.36 SMLT 0.1141 0.2178 0.4596 0.0771 0.26 兽02 表4数据集yeast上各算法的实验结果 0.30 0.22 Table 4 The summary results of four algorithms on yeast .10.20.30.40.5 02810.203040.5 dataset 已标记样本集比例 已标记样本集比例 (a)Hamming Loss (b)One-Error Hamming One- 算法 Ranking Coverage Loss Error L088 2.1 0.24 MLkNN 0.2043 0.2356 6.4256 0.1733 1.9 0.20 1.8 RankSVM 0.2084 0.2190 6.3884 0.1778 1> 1.6 0.16 TRAM 0.2214 0.33476.5000 0.1879 0.10.20.30.4 0.5 .10.2 0.30.40.5 已标记样本集比例 已标记样本集比例 SMLT 0.2105 0.2172 6.31680.1681 (c)Coverage (d)Ranking Loss 图2数据集emotions在4项评估指标上的实验结果 表5数据集enron上各算法的实验结果 Fig.2 The summary results of four evaluation metrics Table 5 The summary results of four algorithms on enron on emotions dataset dataset One- 算法 Hamming Ranking Coverage 0.130 0.29m Loss Error Loss sso 0.125 0.27 MLkNN 0.0587 0.3706 15.3000 0.1048 月02 RankSVM 0.0747 0.3559 14.0659 0.0996 0.2 0.1 0.20.30.40.5 0.10.20.30.40.5 TRAM 0.0533 0.2412 13.8529 0.0875 已标记样本集比例 已标记样本集比伤例 (a)Hamming Loss (b)One-Error SMLT 0.0488 0.1647 13.6528 0.0857 0.60 0.11r 0.55 0.10 通过分析表2~5,在emotions和enron这2个数 0.50 0.09 据集上,提出的算法SMLT在4个评估指标上都优 于其他算法,而在scene数据集上有2个评估指标 0.4510203040 0.0 0.10.20.30.40.5 优于其他算法,但在Hamming Loss和Ranking loss 已标记样本集比例 已标记样本集比例 上略差于其他算法,在yeast数据集上有3个评估指 (c)Coverage (d)Ranking Loss 标优于其他算法,仅在Hamming Loss上略差于其他 图3数据集scene在4项评估指标上的实验结果 算法可能的原因是本文提出的算法充分利用了已 Fig.3 The summary results of four evaluation metrics 标记样本集和未标记样本集的信息,这要比不利用 on scene dataset 已标记样本集或者单纯只利用已标记样本集的信表 3 数据集 scene 上各算法的实验结果 Table 3 The summary results of four algorithms on scene dataset 算法 Hamming Loss One⁃ Error Coverage Ranking Loss MLkNN 0.098 9 0.253 1 0.560 2 0.095 5 RankSVM 0.112 7 0.232 4 0.473 0 0.076 8 TRAM 0.101 0 0.269 7 0.510 4 0.085 4 SMLT 0.114 1 0.217 8 0.459 6 0.077 1 表 4 数据集 yeast 上各算法的实验结果 Table 4 The summary results of four algorithms on yeast dataset 算法 Hamming Loss One⁃ Error Coverage Ranking Loss MLkNN 0.204 3 0.235 6 6.425 6 0.173 3 RankSVM 0.208 4 0.219 0 6.388 4 0.177 8 TRAM 0.221 4 0.334 7 6.500 0 0.187 9 SMLT 0.210 5 0.217 2 6.316 8 0.168 1 表 5 数据集 enron 上各算法的实验结果 Table 5 The summary results of four algorithms on enron dataset 算法 Hamming Loss One⁃ Error Coverage Ranking Loss MLkNN 0.058 7 0.370 6 15.300 0 0.104 8 RankSVM 0.074 7 0.355 9 14.065 9 0.099 6 TRAM 0.053 3 0.241 2 13.852 9 0.087 5 SMLT 0.048 8 0.164 7 13.652 8 0.085 7 通过分析表 2~5,在 emotions 和 enron 这 2 个数 据集上,提出的算法 SMLT 在 4 个评估指标上都优 于其他算法,而在 scene 数据集上有 2 个评估指标 优于其他算法,但在 Hamming Loss 和 Ranking loss 上略差于其他算法,在 yeast 数据集上有 3 个评估指 标优于其他算法,仅在 Hamming Loss 上略差于其他 算法.可能的原因是本文提出的算法充分利用了已 标记样本集和未标记样本集的信息,这要比不利用 已标记样本集或者单纯只利用已标记样本集的信 息,更能提高分类算法的性能. 为了进一步验证已标记样本集的规模对 SMLT 算法的影响,在 4 个数据集上分别进行实验.训练样 本集和测试样本集的构成方法与上文实验相同,但 是已标记样本集占训练数据集的比例依次调整为 10%、20%、30%、40%和 50%时,SMLT 算法在 4 项 评估指标上的取值与已标记样本集比例的关系如图 2~5 所示. 图 2 数据集 emotions 在 4 项评估指标上的实验结果 Fig.2 The summary results of four evaluation metrics on emotions dataset 图 3 数据集 scene 在 4 项评估指标上的实验结果 Fig.3 The summary results of four evaluation metrics on scene dataset 第 5 期 刘杨磊,等:基于 Tri⁃training 的半监督多标记学习算法 ·443·