正在加载图片...
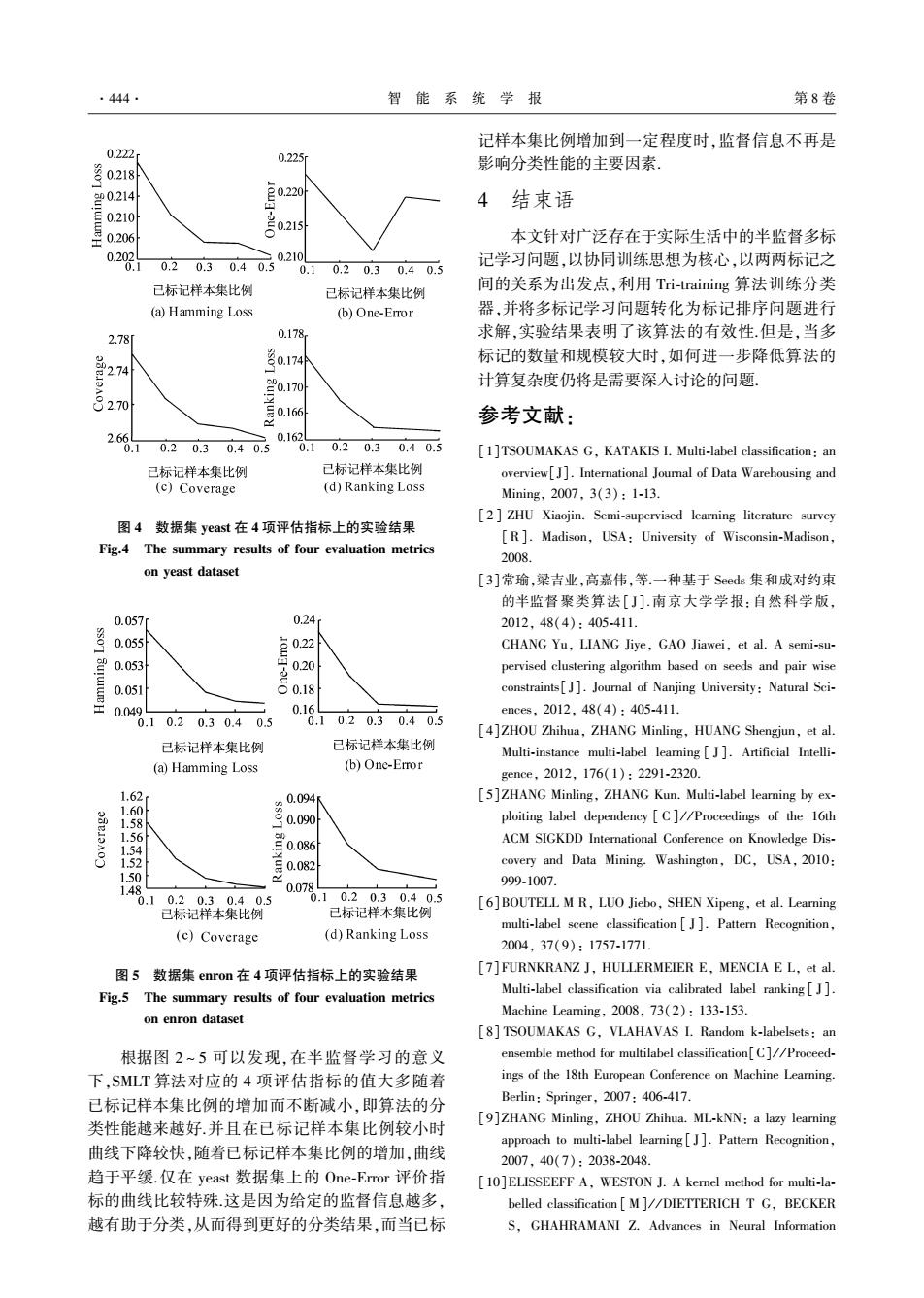
·444. 智能系统学报 第8卷 记样本集比例增加到一定程度时,监督信息不再是 0.222 0.225 o218i 影响分类性能的主要因素, 4结束语 写0.210 里0206 021s 本文针对广泛存在于实际生活中的半监督多标 0.202 0.210 .1 0.20.3 0.40.5 0.10.20.30.40.5 记学习问题,以协同训练思想为核心,以两两标记之 已标记样本集比例 已标记样本集比例 间的关系为出发点,利用Tri-training算法训练分类 (a)Hamming Loss (b)One-Eror 器,并将多标记学习问题转化为标记排序问题进行 2.78 0.178 求解,实验结果表明了该算法的有效性.但是,当多 标记的数量和规模较大时,如何进一步降低算法的 计算复杂度仍将是需要深入讨论的问题. 2.70 号0.166 参考文献: 2.66 0162 .1 0.20.30.40.5 .10.20.30.40.5 [1]TSOUMAKAS G,KATAKIS I.Multi-label classification:an 已标记样本集比例 已标记样本集比例 overview[]].International Journal of Data Warehousing and (c)Coverage (d)Ranking Loss Mining,2007,3(3):1-l3, [2]ZHU Xiaojin.Semi-supervised learning literature survey 图4数据集yeast在4项评估指标上的实验结果 [R].Madison,USA:University of Wisconsin-Madison, Fig.4 The summary results of four evaluation metrics 2008. on yeast dataset 「31常瑜,梁吉业,高嘉伟,等.一种基于Seeds集和成对约束 的半监督聚类算法[J].南京大学学报:自然科学版 0.057 0.24 2012,48(4):405-411. 0.055 CHANG Yu,LIANG Jiye,GAO Jiawei,et al.A semi-su- 0.053 0.20 pervised clustering algorithm based on seeds and pair wise 0.051 号o constraints[J].Journal of Nanjing University:Natural Sci- 0.049 0.16 ences.2012.48(4):405-411. .10.2 0.30.40.5 0.10.20.30.40.5 [4]ZHOU Zhihua,ZHANG Minling,HUANG Shengjun,et al. 已标记样本集比例 已标记样本集比例 Multi-instance multi-label learning J].Artificial Intelli- (a)Hamming Loss (b)One-Error gence,2012,176(1):2291-2320. 1.62 Q094 [5]ZHANG Minling,ZHANG Kun.Multi-label learing by ex- 1.60 1.58 0.090 ploiting label dependency C]//Proceedings of the 16th 1.56 ACM SIGKDD International Conference on Knowledge Dis- 1.54 1.52 covery and Data Mining.Washington,DC,USA,2010: 1.50 999-1007. 1.4 0.07 0.10.20.30.40.5 0.10.20.30.40.5 [6]BOUTELL M R,LUO Jiebo,SHEN Xipeng,et al.Learning 已标记样本集比例 已标记样本集比例 multi-label scene classification J].Pattern Recognition, (c)Coverage (d)Ranking Loss 2004,37(9):1757-1771. 图5数据集enron在4项评估指标上的实验结果 [7]FURNKRANZ J,HULLERMEIER E,MENCIA E L,et al. Fig.5 The summary results of four evaluation metrics Multi-label classification via calibrated label ranking J]. on enron dataset Machine Learning,2008,73(2):133-153. [8]TSOUMAKAS G,VLAHAVAS I.Random k-labelsets:an 根据图2~5可以发现,在半监督学习的意义 ensemble method for multilabel classification[C]//Proceed- 下,SMLT算法对应的4项评估指标的值大多随着 ings of the 18th European Conference on Machine Learning. 已标记样本集比例的增加而不断减小,即算法的分 Berlin:Springer,2007:406-417. 类性能越来越好.并且在已标记样本集比例较小时 [9]ZHANG Minling,ZHOU Zhihua.ML-kNN:a lazy learning approach to multi-label learning[J].Pattern Recognition, 曲线下降较快,随着已标记样本集比例的增加,曲线 2007,40(7):2038-2048. 趋于平缓.仅在yeast数据集上的One-Emor评价指 [10]ELISSEEFF A,WESTON J.A kernel method for multi-la- 标的曲线比较特殊这是因为给定的监督信息越多, belled classification M]//DIETTERICH T G,BECKER 越有助于分类,从而得到更好的分类结果,而当已标 S,GHAHRAMANI Z.Advances in Neural Information图 4 数据集 yeast 在 4 项评估指标上的实验结果 Fig.4 The summary results of four evaluation metrics on yeast dataset 图 5 数据集 enron 在 4 项评估指标上的实验结果 Fig.5 The summary results of four evaluation metrics on enron dataset 根据图 2 ~ 5 可以发现,在半监督学习的意义 下,SMLT 算法对应的 4 项评估指标的值大多随着 已标记样本集比例的增加而不断减小,即算法的分 类性能越来越好.并且在已标记样本集比例较小时 曲线下降较快,随着已标记样本集比例的增加,曲线 趋于平缓.仅在 yeast 数据集上的 One⁃Error 评价指 标的曲线比较特殊.这是因为给定的监督信息越多, 越有助于分类,从而得到更好的分类结果,而当已标 记样本集比例增加到一定程度时,监督信息不再是 影响分类性能的主要因素. 4 结束语 本文针对广泛存在于实际生活中的半监督多标 记学习问题,以协同训练思想为核心,以两两标记之 间的关系为出发点,利用 Tri⁃training 算法训练分类 器,并将多标记学习问题转化为标记排序问题进行 求解,实验结果表明了该算法的有效性.但是,当多 标记的数量和规模较大时,如何进一步降低算法的 计算复杂度仍将是需要深入讨论的问题. 参考文献: [1]TSOUMAKAS G, KATAKIS I. Multi⁃label classification: an overview[J]. International Journal of Data Warehousing and Mining, 2007, 3(3): 1⁃13. [2 ] ZHU Xiaojin. Semi⁃supervised learning literature survey [R]. Madison, USA: University of Wisconsin⁃Madison, 2008. [3]常瑜,梁吉业,高嘉伟,等.一种基于 Seeds 集和成对约束 的半监督聚类算法[ J]. 南京大学学报:自然科学版, 2012, 48(4): 405⁃411. CHANG Yu, LIANG Jiye, GAO Jiawei, et al. A semi⁃su⁃ pervised clustering algorithm based on seeds and pair wise constraints[ J]. Journal of Nanjing University: Natural Sci⁃ ences, 2012, 48(4): 405⁃411. [4]ZHOU Zhihua, ZHANG Minling, HUANG Shengjun, et al. Multi⁃instance multi⁃label learning [ J ]. Artificial Intelli⁃ gence, 2012, 176(1): 2291⁃2320. [5]ZHANG Minling, ZHANG Kun. Multi⁃label learning by ex⁃ ploiting label dependency [ C] / / Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Dis⁃ covery and Data Mining. Washington, DC, USA, 2010: 999⁃1007. [6]BOUTELL M R, LUO Jiebo, SHEN Xipeng, et al. Learning multi⁃label scene classification [ J ]. Pattern Recognition, 2004, 37(9): 1757⁃1771. [7]FURNKRANZ J, HULLERMEIER E, MENCIA E L, et al. Multi⁃label classification via calibrated label ranking [ J]. Machine Learning, 2008, 73(2): 133⁃153. [8] TSOUMAKAS G, VLAHAVAS I. Random k⁃labelsets: an ensemble method for multilabel classification[C] / / Proceed⁃ ings of the 18th European Conference on Machine Learning. Berlin: Springer, 2007: 406⁃417. [9]ZHANG Minling, ZHOU Zhihua. ML⁃kNN: a lazy learning approach to multi⁃label learning [ J]. Pattern Recognition, 2007, 40(7): 2038⁃2048. [10]ELISSEEFF A, WESTON J. A kernel method for multi⁃la⁃ belled classification [ M] / / DIETTERICH T G, BECKER S, GHAHRAMANI Z. Advances in Neural Information ·444· 智 能 系 统 学 报 第 8 卷