正在加载图片...
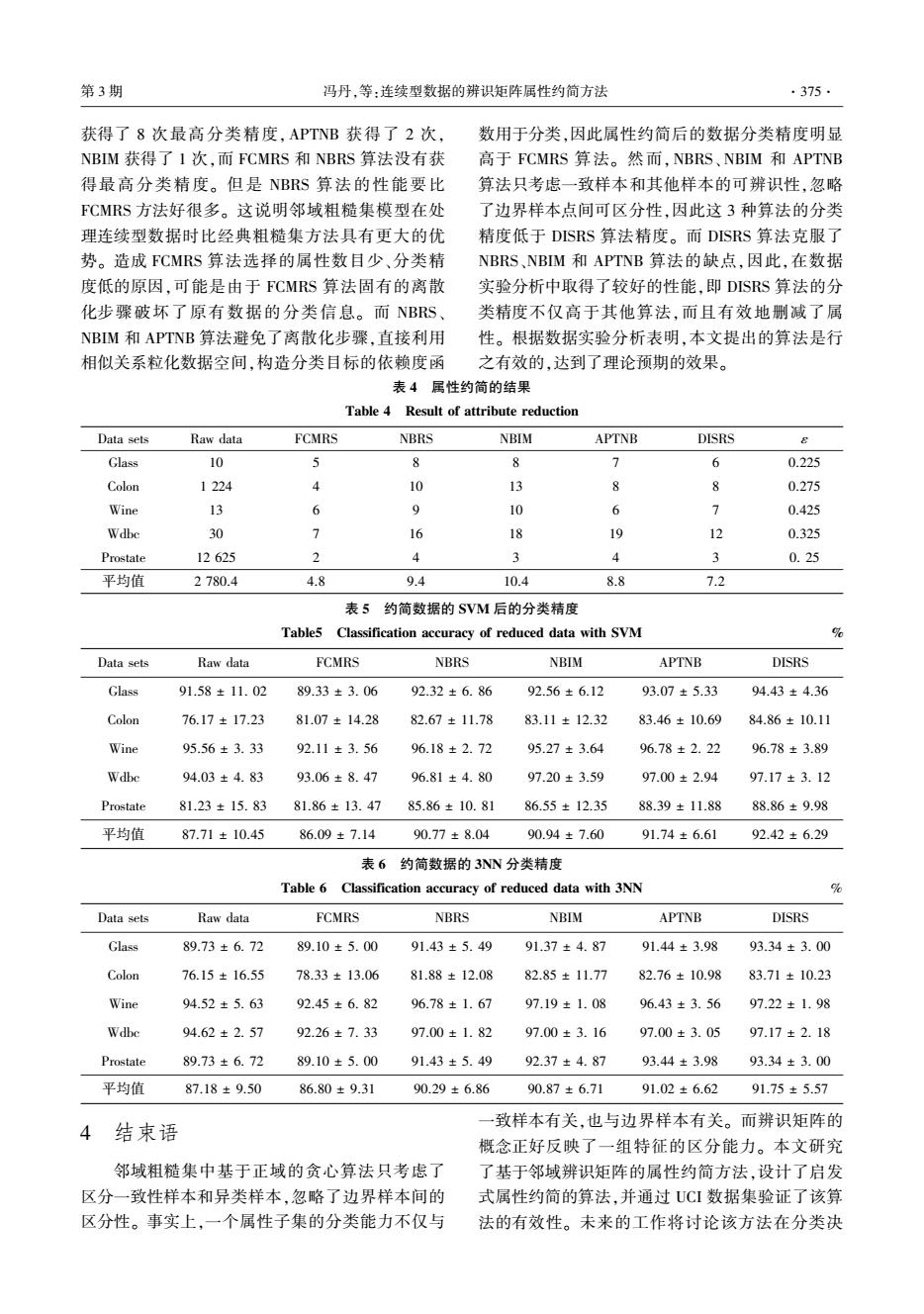
第3期 冯丹,等:连续型数据的辨识矩阵属性约简方法 ·375· 获得了8次最高分类精度,APTNB获得了2次, 数用于分类,因此属性约简后的数据分类精度明显 NBIM获得了1次,而FCMRS和NBRS算法没有获 高于FCMRS算法。然而,NBRS、NBIM和APTNB 得最高分类精度。但是NBRS算法的性能要比 算法只考虑一致样本和其他样本的可辨识性,忽略 FCMRS方法好很多。这说明邻域粗糙集模型在处 了边界样本点间可区分性,因此这3种算法的分类 理连续型数据时比经典粗糙集方法具有更大的优 精度低于DISRS算法精度。而DISRS算法克服了 势。造成FCMRS算法选择的属性数目少、分类精 NBRS、NBM和APTNB算法的缺点,因此,在数据 度低的原因,可能是由于FCMRS算法固有的离散 实验分析中取得了较好的性能,即DISRS算法的分 化步骤破坏了原有数据的分类信息。而NBRS、 类精度不仅高于其他算法,而且有效地删减了属 NBM和APTNB算法避免了离散化步骤,直接利用 性。根据数据实验分析表明,本文提出的算法是行 相似关系粒化数据空间,构造分类目标的依赖度函 之有效的,达到了理论预期的效果。 表4属性约简的结果 Table 4 Result of attribute reduction Data sets Raw data FCMRS NBRS NBIM APTNB DISRS Glass 10 J 8 6 0.225 Colon 1224 4 10 13 8 8 0.275 Wine 13 6 9 10 6 > 0.425 Wdbe 30 > 16 8 19 12 0.325 Prostate 12625 2 4 3 4 3 0.25 平均值 2780.4 48 9.4 10.4 8.8 7.2 表5约简数据的SVM后的分类精度 Table5 Classification accuracy of reduced data with SVM % Data sets Raw data FCMRS NBRS NBIM APTNB DISRS Glass 91.58±11.02 89.33±3.06 92.32±6.86 92.56±6.12 93.07±5.33 94.43±4.36 Colon 76.17±17.23 81.07±14.28 82.67±11.78 83.11±12.32 83.46±10.69 84.86±10.11 Wine 95.56±3.33 92.11±3.56 96.18±2.72 95.27±3.64 96.78±2.22 96.78±3.89 Wdbe 94.03±4.83 93.06±8.47 96.81±4.80 97.20±3.59 97.00±2.94 97.17±3.12 Prostate 81.23±15.83 81.86±13.47 85.86±10.81 86.55±12.35 88.39±11.88 88.86±9.98 平均值 87.71±10.45 86.09±7.14 90.77±8.04 90.94±7.60 91.74±6.61 92.42±6.29 表6约简数据的3NN分类精度 Table 6 Classification accuracy of reduced data with 3NN 号 Data sets Raw data FCMRS NBRS NBIM APTNB DISRS Glass 89.73±6.72 89.10±5.00 91.43±5.49 91.37±4.87 91.44±3.98 93.34±3.00 Colon 76.15±16.55 78.33±13.06 81.88±12.08 82.85±11.77 82.76±10.98 83.71±10.23 Wine 94.52±5.63 92.45±6.82 96.78±1.67 97.19±1.08 96.43±3.56 97.22±1.98 Wdbe 94.62±2.57 92.26±7.33 97.00±1.82 97.00±3.16 97.00±3.05 97.17±2.18 Prostate 89.73±6.72 89.10±5.00 91.43±5.49 92.37±4.87 93.44±3.98 93.34±3.00 平均值 87.18±9.50 86.80±9.31 90.29±6.86 90.87±6.71 91.02±6.62 91.75±5.57 致样本有关,也与边界样本有关。而辨识矩阵的 4 结束语 概念正好反映了一组特征的区分能力。本文研究 邻域粗糙集中基于正域的贪心算法只考虑了 了基于邻域辨识矩阵的属性约简方法,设计了启发 区分一致性样本和异类样本,忽略了边界样本间的 式属性约简的算法,并通过UCI数据集验证了该算 区分性。事实上,一个属性子集的分类能力不仅与 法的有效性。未来的工作将讨论该方法在分类决获得了 8 次最高分类精度,APTNB 获得了 2 次, NBIM 获得了 1 次,而 FCMRS 和 NBRS 算法没有获 得最高分类精度。 但是 NBRS 算法的性能要比 FCMRS 方法好很多。 这说明邻域粗糙集模型在处 理连续型数据时比经典粗糙集方法具有更大的优 势。 造成 FCMRS 算法选择的属性数目少、分类精 度低的原因,可能是由于 FCMRS 算法固有的离散 化步骤破坏了原有数据的分类信息。 而 NBRS、 NBIM 和 APTNB 算法避免了离散化步骤,直接利用 相似关系粒化数据空间,构造分类目标的依赖度函 数用于分类,因此属性约简后的数据分类精度明显 高于 FCMRS 算法。 然而,NBRS、NBIM 和 APTNB 算法只考虑一致样本和其他样本的可辨识性,忽略 了边界样本点间可区分性,因此这 3 种算法的分类 精度低于 DISRS 算法精度。 而 DISRS 算法克服了 NBRS、NBIM 和 APTNB 算法的缺点,因此,在数据 实验分析中取得了较好的性能,即 DISRS 算法的分 类精度不仅高于其他算法,而且有效地删减了属 性。 根据数据实验分析表明,本文提出的算法是行 之有效的,达到了理论预期的效果。 表 4 属性约简的结果 Table 4 Result of attribute reduction Data sets Raw data FCMRS NBRS NBIM APTNB DISRS ε Glass 10 5 8 8 7 6 0.225 Colon 1 224 4 10 13 8 8 0.275 Wine 13 6 9 10 6 7 0.425 Wdbc 30 7 16 18 19 12 0.325 Prostate 12 625 2 4 3 4 3 0. 25 平均值 2 780.4 4.8 9.4 10.4 8.8 7.2 表 5 约简数据的 SVM 后的分类精度 Table5 Classification accuracy of reduced data with SVM % Data sets Raw data FCMRS NBRS NBIM APTNB DISRS Glass 91.58 ± 11. 02 89.33 ± 3. 06 92.32 ± 6. 86 92.56 ± 6.12 93.07 ± 5.33 94.43 ± 4.36 Colon 76.17 ± 17.23 81.07 ± 14.28 82.67 ± 11.78 83.11 ± 12.32 83.46 ± 10.69 84.86 ± 10.11 Wine 95.56 ± 3. 33 92.11 ± 3. 56 96.18 ± 2. 72 95.27 ± 3.64 96.78 ± 2. 22 96.78 ± 3.89 Wdbc 94.03 ± 4. 83 93.06 ± 8. 47 96.81 ± 4. 80 97.20 ± 3.59 97.00 ± 2.94 97.17 ± 3. 12 Prostate 81.23 ± 15. 83 81.86 ± 13. 47 85.86 ± 10. 81 86.55 ± 12.35 88.39 ± 11.88 88.86 ± 9.98 平均值 87.71 ± 10.45 86.09 ± 7.14 90.77 ± 8.04 90.94 ± 7.60 91.74 ± 6.61 92.42 ± 6.29 表 6 约简数据的 3NN 分类精度 Table 6 Classification accuracy of reduced data with 3NN % Data sets Raw data FCMRS NBRS NBIM APTNB DISRS Glass 89.73 ± 6. 72 89.10 ± 5. 00 91.43 ± 5. 49 91.37 ± 4. 87 91.44 ± 3.98 93.34 ± 3. 00 Colon 76.15 ± 16.55 78.33 ± 13.06 81.88 ± 12.08 82.85 ± 11.77 82.76 ± 10.98 83.71 ± 10.23 Wine 94.52 ± 5. 63 92.45 ± 6. 82 96.78 ± 1. 67 97.19 ± 1. 08 96.43 ± 3. 56 97.22 ± 1. 98 Wdbc 94.62 ± 2. 57 92.26 ± 7. 33 97.00 ± 1. 82 97.00 ± 3. 16 97.00 ± 3. 05 97.17 ± 2. 18 Prostate 89.73 ± 6. 72 89.10 ± 5. 00 91.43 ± 5. 49 92.37 ± 4. 87 93.44 ± 3.98 93.34 ± 3. 00 平均值 87.18 ± 9.50 86.80 ± 9.31 90.29 ± 6.86 90.87 ± 6.71 91.02 ± 6.62 91.75 ± 5.57 4 结束语 邻域粗糙集中基于正域的贪心算法只考虑了 区分一致性样本和异类样本,忽略了边界样本间的 区分性。 事实上,一个属性子集的分类能力不仅与 一致样本有关,也与边界样本有关。 而辨识矩阵的 概念正好反映了一组特征的区分能力。 本文研究 了基于邻域辨识矩阵的属性约简方法,设计了启发 式属性约简的算法,并通过 UCI 数据集验证了该算 法的有效性。 未来的工作将讨论该方法在分类决 第 3 期 冯丹,等:连续型数据的辨识矩阵属性约简方法 ·375·