正在加载图片...
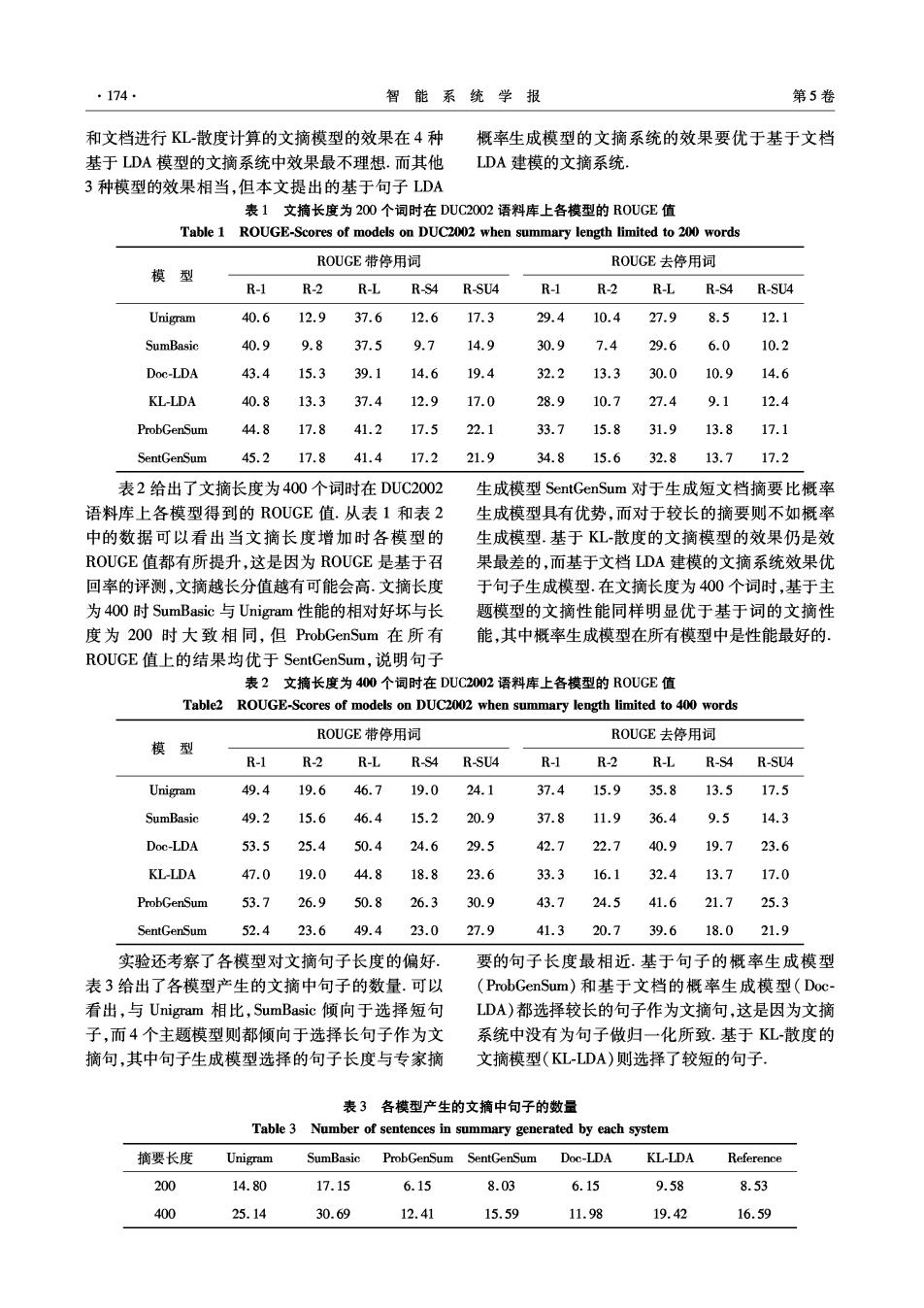
174 智能系统学报 第5卷 和文档进行KL-散度计算的文摘模型的效果在4种 概率生成模型的文摘系统的效果要优于基于文档 基于LDA模型的文摘系统中效果最不理想.而其他 LDA建模的文摘系统 3种模型的效果相当,但本文提出的基于句子LDA 表1文摘长度为200个词时在DUC2002语料库上各模型的R0UGE值 Table 1 ROUGE-Scores of models on DUC2002 when summary length limited to 200 words ROUGE带停用词 ROUGE去停用词 模 型 R-1 R-2 R-L R-S4 R-SU4 R-1 R-2 R-L R-S4 R-SU4 Unigram 40.6 12.9 37.6 12.6 17.3 29.4 10.4 27.9 8.5 12.1 SumBasic 40.9 9.8 37.5 9.7 14.9 30.9 7.4 29.6 6.0 10.2 Doc-LDA 43.4 15.3 39.1 14.6 19.4 32.2 13.3 30.0 10.9 14.6 KL-LDA 40.8 13.3 37.4 12.9 17.0 28.9 10.7 27.4 9.1 12.4 ProbGenSum 44.8 17.8 41.2 17.5 22.1 33.7 15.8 31.9 13.8 17.1 SentGenSum 45.2 17.8 41.4 17.2 21.9 34.815.6 32.8 13.717.2 表2给出了文摘长度为400个词时在DUC2002 生成模型SentGenSum对于生成短文档摘要比概率 语料库上各模型得到的ROUGE值.从表1和表2 生成模型具有优势,而对于较长的摘要则不如概率 中的数据可以看出当文摘长度增加时各模型的 生成模型.基于KL-散度的文摘模型的效果仍是效 ROUGE值都有所提升,这是因为ROUGE是基于召 果最差的,而基于文档LDA建模的文摘系统效果优 回率的评测,文摘越长分值越有可能会高.文摘长度 于句子生成模型.在文摘长度为400个词时,基于主 为400时SumBasic与Unigram性能的相对好坏与长 题模型的文摘性能同样明显优于基于词的文摘性 度为200时大致相同,但ProbGenSum在所有 能,其中概率生成模型在所有模型中是性能最好的、 ROUGE值上的结果均优于SentGenSum,说明句子 表2文摘长度为400个词时在DUC2002语料库上各模型的R0UGE值 Table2 ROUGE-Scores of models on DUC2002 when summary length limited to 400 words ROUGE带停用词 ROUGE去停用词 模型 R-1 R-2 R-L R-S4 R-SU4 R-1 R-2 R-L R-S4 R-SU4 Unigram 49.4 19.6 46.7 19.0 24.1 37.4 15.9 35.8 13.5 17.5 SumBasic 49.2 15.6 46.4 15.2 20.9 37.8 11.9 36.4 9.5 14.3 Doc-LDA 53.5 25.4 50.4 24.6 29.5 42.7 22.7 40.9 19.7 23.6 KL-LDA 47.0 19.0 44.8 18.8 23.6 33.3 16.1 32.4 13.7 17.0 ProbGenSum 53.7 26.9 50.8 26.3 30.9 43.7 24.5 41.6 21.7 25.3 SentGenSum 52.4 23.6 49.4 23.0 27.9 41.3 20.7 39.6 18.0 21.9 实验还考察了各模型对文摘句子长度的偏好 要的句子长度最相近.基于句子的概率生成模型 表3给出了各模型产生的文摘中句子的数量.可以 (ProbGenSum)和基于文档的概率生成模型(Doc- 看出,与Unigram相比,SumBasic倾向于选择短句 LDA)都选择较长的句子作为文摘句,这是因为文摘 子,而4个主题模型则都倾向于选择长句子作为文 系统中没有为句子做归一化所致.基于KL-散度的 摘句,其中句子生成模型选择的句子长度与专家摘 文摘模型(KL-LDA)则选择了较短的句子 表3各模型产生的文摘中句子的数量 Table 3 Number of sentences in summary generated by each system 摘要长度 Unigram SumBasic ProbGenSum SentGenSum Doc-LDA KL-LDA Reference 200 14.80 17.15 6.15 8.03 6.15 9.58 8.53 400 25.14 30.69 12.41 15.59 11.98 19.42 16.59