正在加载图片...
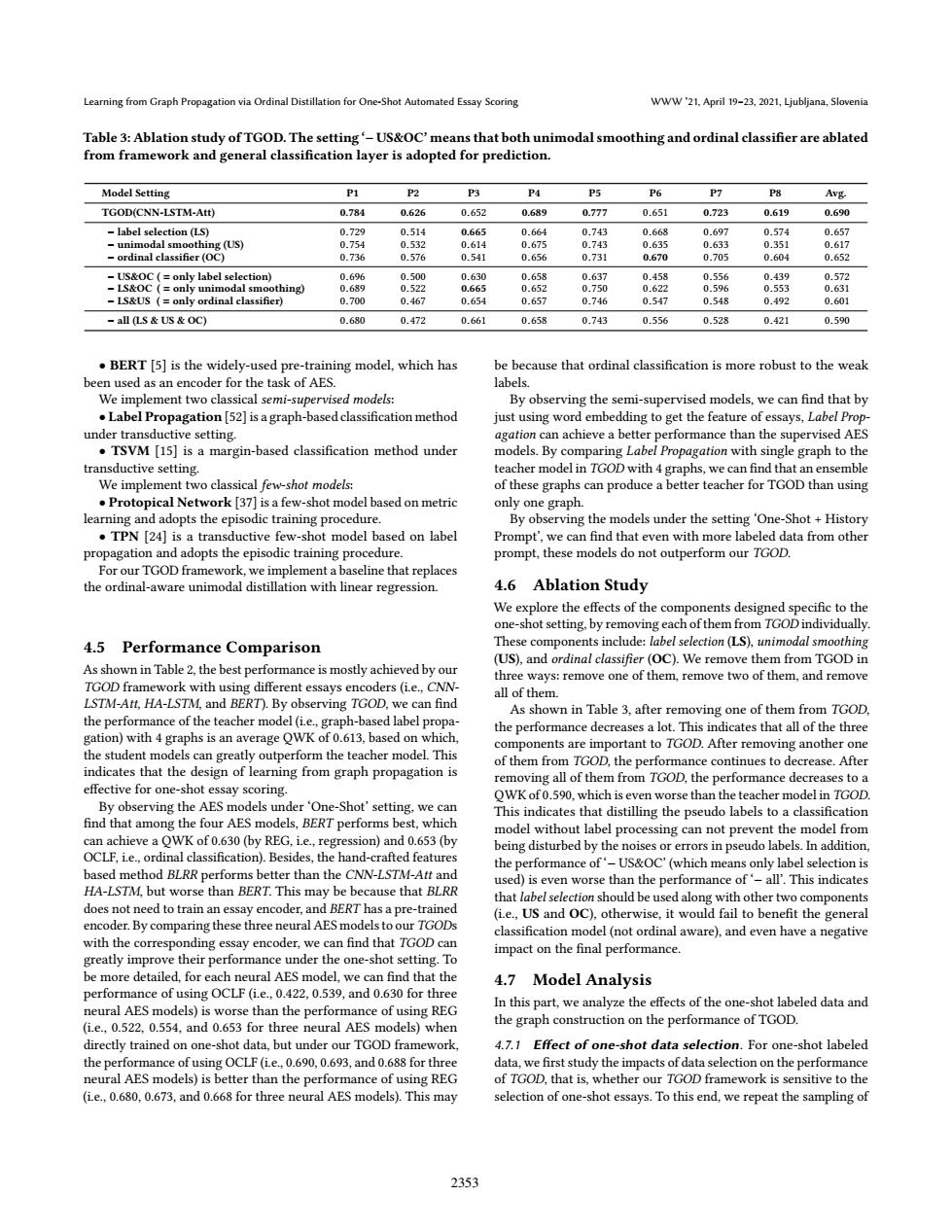
Learning from Graph Propagation via Ordinal Distillation for One-Shot Automated Essay Scoring WWW'21,April 19-23,2021,Ljubljana,Slovenia Table 3:Ablation study of TGOD.The setting-US&OC'means that both unimodal smoothing and ordinal classifier are ablated from framework and general classification layer is adopted for prediction. Model Setting P2 P3 P4 P5 P6 P7 P8 Avg. TGOD(CNN-LSTM-Att) 0.784 0.626 0.652 0.689 0.777 0.651 0.723 0.619 0.690 label selection(LS) 0.729 0.514 0.665 0.664 0.743 0.668 0.697 0.574 0.657 -unimodal smoothing (US) 0.754 0.532 0.614 0.675 0.743 0.635 0.633 0.351 0.617 ordinal classifier(OC) 0.736 0.576 0.541 0.656 0.731 0.670 0.705 0.604 0.652 US&OC(=only label selection) 0.696 0.500 0.630 0.658 0.637 0.458 0.556 0.439 0.572 -LS&OC (only unimodal smoothing) 0.689 0.522 0.665 0.652 0.750 0.622 0.596 0.553 0.631 -LS&US (only ordinal classifier) 0.700 0.467 0.654 0.657 0.746 0.547 0.548 0.492 0.601 all (LS US OC) 0.680 0.472 0.661 0.658 0.743 0.556 0.528 0.421 0.590 BERT [5]is the widely-used pre-training model,which has be because that ordinal classification is more robust to the weak been used as an encoder for the task of AES. labels. We implement two classical semi-supervised models: By observing the semi-supervised models,we can find that by .Label Propagation [52]is a graph-based classification method just using word embedding to get the feature of essays,Label Prop- under transductive setting. agation can achieve a better performance than the supervised AES TSVM [15]is a margin-based classification method under models.By comparing Label Propagation with single graph to the transductive setting. teacher model in TGOD with 4 graphs,we can find that an ensemble We implement two classical few-shot models: of these graphs can produce a better teacher for TGOD than using Protopical Network [37]is a few-shot model based on metric only one graph. learning and adopts the episodic training procedure. By observing the models under the setting 'One-Shot History TPN [24]is a transductive few-shot model based on label Prompt',we can find that even with more labeled data from other propagation and adopts the episodic training procedure. prompt,these models do not outperform our TGOD. For our TGOD framework,we implement a baseline that replaces the ordinal-aware unimodal distillation with linear regression. 4.6 Ablation Study We explore the effects of the components designed specific to the one-shot setting,by removing each of them from TGOD individually. 4.5 Performance Comparison These components include:label selection(LS),unimodal smoothing (US),and ordinal classifier (OC).We remove them from TGOD in As shown in Table 2,the best performance is mostly achieved by our three ways:remove one of them,remove two of them,and remove TGOD framework with using different essays encoders(i.e.,CNN all of them. LSTM-Att.HA-LSTM.and BERT).By observing TGOD.we can find As shown in Table 3,after removing one of them from TGOD, the performance of the teacher model(ie.,graph-based label propa- gation)with 4 graphs is an average QWK of 0.613,based on which, the performance decreases a lot.This indicates that all of the three components are important to TGOD.After removing another one the student models can greatly outperform the teacher model.This of them from TGOD,the performance continues to decrease.After indicates that the design of learning from graph propagation is removing all of them from TGOD,the performance decreases to a effective for one-shot essay scoring. OWK of 0.590,which is even worse than the teacher model in TGOD. By observing the AES models under'One-Shot'setting,we can This indicates that distilling the pseudo labels to a classification find that among the four AES models,BERT performs best,which model without label processing can not prevent the model from can achieve a OWK of 0.630(by REG,ie.,regression)and 0.653 (by being disturbed by the noises or errors in pseudo labels.In addition, OCLF,i.e.,ordinal classification).Besides,the hand-crafted features the performance of'-US&OC'(which means only label selection is based method BLRR performs better than the CNN-LSTM-Att and used)is even worse than the performance of'-all'.This indicates HA-LSTM,but worse than BERT.This may be because that BLRR that label selection should be used along with other two components does not need to train an essay encoder,and BERT has a pre-trained (i.e.,US and OC),otherwise,it would fail to benefit the general encoder.By comparing these three neural AES models to our TGODs classification model(not ordinal aware),and even have a negative with the corresponding essay encoder,we can find that TGOD can impact on the final performance. greatly improve their performance under the one-shot setting.To be more detailed,for each neural AES model,we can find that the 4.7 Model Analysis performance of using OCLF(ie.,0.422,0.539,and 0.630 for three neural AES models)is worse than the performance of using REG In this part,we analyze the effects of the one-shot labeled data and (i.e.,0.522,0.554,and 0.653 for three neural AES models)when the graph construction on the performance of TGOD. directly trained on one-shot data,but under our TGOD framework, 4.7.1 Effect of one-shot data selection.For one-shot labeled the performance of using OCLF (ie..0.690,0.693,and 0.688 for three data.we first study the impacts of data selection on the performance neural AES models)is better than the performance of using REG of TGOD,that is,whether our TGOD framework is sensitive to the (i.e.,0.680,0.673,and 0.668 for three neural AES models).This may selection of one-shot essays.To this end,we repeat the sampling of 2353Learning from Graph Propagation via Ordinal Distillation for One-Shot Automated Essay Scoring WWW ’21, April 19–23, 2021, Ljubljana, Slovenia Table 3: Ablation study of TGOD. The setting ‘− US&OC’ means that both unimodal smoothing and ordinal classifier are ablated from framework and general classification layer is adopted for prediction. Model Setting P1 P2 P3 P4 P5 P6 P7 P8 Avg. TGOD(CNN-LSTM-Att) 0.784 0.626 0.652 0.689 0.777 0.651 0.723 0.619 0.690 − label selection (LS) 0.729 0.514 0.665 0.664 0.743 0.668 0.697 0.574 0.657 − unimodal smoothing (US) 0.754 0.532 0.614 0.675 0.743 0.635 0.633 0.351 0.617 − ordinal classifier (OC) 0.736 0.576 0.541 0.656 0.731 0.670 0.705 0.604 0.652 − US&OC ( = only label selection) 0.696 0.500 0.630 0.658 0.637 0.458 0.556 0.439 0.572 − LS&OC ( = only unimodal smoothing) 0.689 0.522 0.665 0.652 0.750 0.622 0.596 0.553 0.631 − LS&US ( = only ordinal classifier) 0.700 0.467 0.654 0.657 0.746 0.547 0.548 0.492 0.601 − all (LS & US & OC) 0.680 0.472 0.661 0.658 0.743 0.556 0.528 0.421 0.590 • BERT [5] is the widely-used pre-training model, which has been used as an encoder for the task of AES. We implement two classical semi-supervised models: • Label Propagation [52] is a graph-based classification method under transductive setting. • TSVM [15] is a margin-based classification method under transductive setting. We implement two classical few-shot models: • Protopical Network [37] is a few-shot model based on metric learning and adopts the episodic training procedure. • TPN [24] is a transductive few-shot model based on label propagation and adopts the episodic training procedure. For our TGOD framework, we implement a baseline that replaces the ordinal-aware unimodal distillation with linear regression. 4.5 Performance Comparison As shown in Table 2, the best performance is mostly achieved by our TGOD framework with using different essays encoders (i.e., CNNLSTM-Att, HA-LSTM, and BERT). By observing TGOD, we can find the performance of the teacher model (i.e., graph-based label propagation) with 4 graphs is an average QWK of 0.613, based on which, the student models can greatly outperform the teacher model. This indicates that the design of learning from graph propagation is effective for one-shot essay scoring. By observing the AES models under ‘One-Shot’ setting, we can find that among the four AES models, BERT performs best, which can achieve a QWK of 0.630 (by REG, i.e., regression) and 0.653 (by OCLF, i.e., ordinal classification). Besides, the hand-crafted features based method BLRR performs better than the CNN-LSTM-Att and HA-LSTM, but worse than BERT. This may be because that BLRR does not need to train an essay encoder, and BERT has a pre-trained encoder. By comparing these three neural AES models to our TGODs with the corresponding essay encoder, we can find that TGOD can greatly improve their performance under the one-shot setting. To be more detailed, for each neural AES model, we can find that the performance of using OCLF (i.e., 0.422, 0.539, and 0.630 for three neural AES models) is worse than the performance of using REG (i.e., 0.522, 0.554, and 0.653 for three neural AES models) when directly trained on one-shot data, but under our TGOD framework, the performance of using OCLF (i.e., 0.690, 0.693, and 0.688 for three neural AES models) is better than the performance of using REG (i.e., 0.680, 0.673, and 0.668 for three neural AES models). This may be because that ordinal classification is more robust to the weak labels. By observing the semi-supervised models, we can find that by just using word embedding to get the feature of essays, Label Propagation can achieve a better performance than the supervised AES models. By comparing Label Propagation with single graph to the teacher model in TGOD with 4 graphs, we can find that an ensemble of these graphs can produce a better teacher for TGOD than using only one graph. By observing the models under the setting ‘One-Shot + History Prompt’, we can find that even with more labeled data from other prompt, these models do not outperform our TGOD. 4.6 Ablation Study We explore the effects of the components designed specific to the one-shot setting, by removing each of them from TGOD individually. These components include: label selection (LS), unimodal smoothing (US), and ordinal classifier (OC). We remove them from TGOD in three ways: remove one of them, remove two of them, and remove all of them. As shown in Table 3, after removing one of them from TGOD, the performance decreases a lot. This indicates that all of the three components are important to TGOD. After removing another one of them from TGOD, the performance continues to decrease. After removing all of them from TGOD, the performance decreases to a QWK of 0.590, which is even worse than the teacher model in TGOD. This indicates that distilling the pseudo labels to a classification model without label processing can not prevent the model from being disturbed by the noises or errors in pseudo labels. In addition, the performance of ‘− US&OC’ (which means only label selection is used) is even worse than the performance of ‘− all’. This indicates that label selection should be used along with other two components (i.e., US and OC), otherwise, it would fail to benefit the general classification model (not ordinal aware), and even have a negative impact on the final performance. 4.7 Model Analysis In this part, we analyze the effects of the one-shot labeled data and the graph construction on the performance of TGOD. 4.7.1 Effect of one-shot data selection. For one-shot labeled data, we first study the impacts of data selection on the performance of TGOD, that is, whether our TGOD framework is sensitive to the selection of one-shot essays. To this end, we repeat the sampling of 2353