正在加载图片...
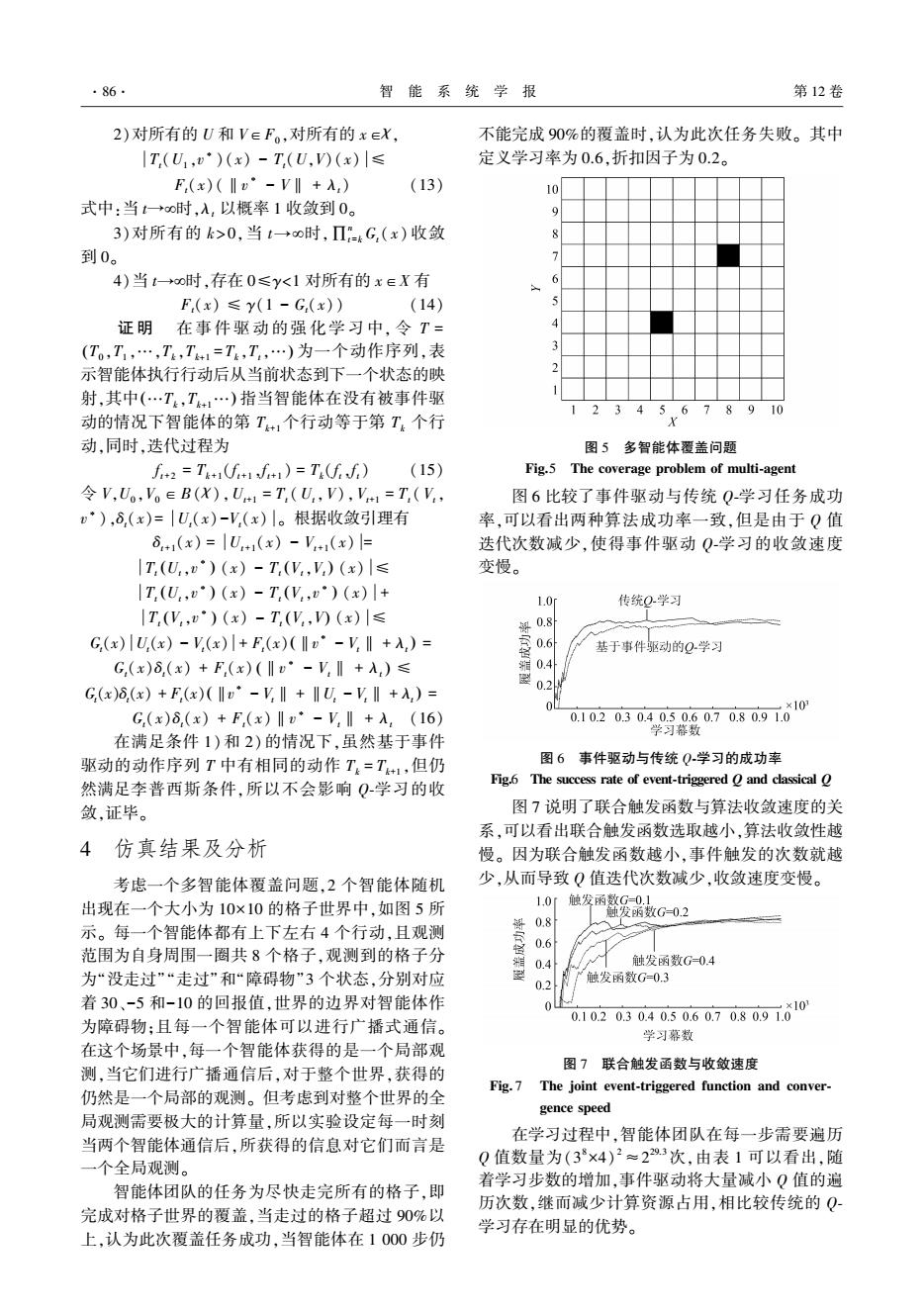
·86 智能系统学报 第12卷 2)对所有的U和V∈F。,对所有的x∈X 不能完成90%的覆盖时,认为此次任务失败。其中 |T(U1,·)(x)-T,(U,V)(x)|≤ 定义学习率为0.6,折扣因子为0.2。 F(x)(‖v°-V‖+入,) (13) 10 式中:当t+o时,入,以概率1收敛到0。 9 3)对所有的k>0,当t→0时,Π4G,(x)收敛 到0。 4)当t→oo时,存在0≤y<1对所有的x∈X有 F(x)≤y(1-G,(x)) (14) 证明在事件驱动的强化学习中,令T= (T,T,…,T,T41=T,T,…)为一个动作序列,表 示智能体执行行动后从当前状态到下一个状态的映 射,其中(…T,T+1…)指当智能体在没有被事件驱 12345678910 动的情况下智能体的第T+,个行动等于第T,个行 X 动,同时,迭代过程为 图5多智能体覆盖问题 f2=T)=T(ff) (15) Fig.5 The coverage problem of multi-agent 令V,Uo,V。∈B(X),U+1=T,(U,V),V1=T(V, 图6比较了事件驱动与传统Q-学习任务成功 ),δ,(x)=|U,(x)-V,(x)|。根据收敛引理有 率,可以看出两种算法成功率一致,但是由于Q值 6+1(x)=|U+1(x)-V+(x)= 迭代次数减少,使得事件驱动Q学习的收敛速度 |T,(U,)(x)-T,(V,V)(x)|≤ 变慢。 |T(U,)(x)-T(V,)(x)|+ 1.0i 传统Q学习 |T,(V,)(x)-T(V,)(x)|≤ G(x)U.(x)-V(x)l+F,(x)(Iv·-V,I+入,)= 基于事件驱动的Q学习 G,(x)8,(x)+F(x)(I·-V,‖+入)≤ 0.2 G,(x)δ,(x)+F(x)(Iv"-V‖+‖U-VI+入,)= G,(x)8,(x)+F,(x)‖·-V‖+入,(16) 0102030405060708091010 学习幕数 在满足条件1)和2)的情况下,虽然基于事件 驱动的动作序列T中有相同的动作T=T+1,但仍 图6事件驱动与传统Q学习的成功率 然满足李普西斯条件,所以不会影响Q学习的收 Fig.6 The success rate of event-triggered O and classical O 敛,证毕。 图7说明了联合触发函数与算法收敛速度的关 系,可以看出联合触发函数选取越小,算法收敛性越 4仿真结果及分析 慢。因为联合触发函数越小,事件触发的次数就越 考虑一个多智能体覆盖问题,2个智能体随机 少,从而导致Q值迭代次数减少,收敛速度变慢。 出现在一个大小为10×10的格子世界中,如图5所 1.0r 0.8 触发函整G-02 示。每一个智能体都有上下左右4个行动,且观测 0.6 范围为自身周围一圈共8个格子,观测到的格子分 0.4 触发函数G-0.4 为“没走过”“走过”和“障碍物”3个状态,分别对应 触发函数G=0.3 0.2 着30、-5和-10的回报值,世界的边界对智能体作 为障碍物:且每一个智能体可以进行广播式通信。 0.10.20304050.60708091610 学习幕数 在这个场景中,每一个智能体获得的是一个局部观 图7联合触发函数与收敛速度 测,当它们进行广播通信后,对于整个世界,获得的 Fig.7 The joint event-triggered function and conver- 仍然是一个局部的观测。但考虑到对整个世界的全 gence speed 局观测需要极大的计算量,所以实验设定每一时刻 当两个智能体通信后,所获得的信息对它们而言是 在学习过程中,智能体团队在每一步需要遍历 Q值数量为(38×4)2≈229.3次,由表1可以看出,随 一个全局观测。 智能体团队的任务为尽快走完所有的格子,即 着学习步数的增加,事件驱动将大量减小Q值的遍 历次数,继而减少计算资源占用,相比较传统的Q 完成对格子世界的覆盖,当走过的格子超过90%以 学习存在明显的优势。 上,认为此次覆盖任务成功,当智能体在1000步仍2)对所有的 U 和 V∈F0 ,对所有的 x∈χ, Tt(U1 ,v ∗ )(x) - Tt(U,V)(x) ≤ Ft(x)(‖v ∗ - V‖ + λt) (13) 式中:当 t→¥时,λt 以概率 1 收敛到 0。 3)对所有的 k > 0,当 t→¥时,∏n t =k Gt( x) 收敛 到 0。 4)当 t→¥时,存在 0≤γ<1 对所有的 x∈X 有 Ft(x) ≤ γ(1 - Gt(x)) (14) 证 明 在 事 件 驱 动 的 强 化 学 习 中, 令 T = T0 ,T1 ,…,Tk,Tk+1 ( = Tk,Tt,…) 为一个动作序列,表 示智能体执行行动后从当前状态到下一个状态的映 射,其中(…Tk,Tk+1…) 指当智能体在没有被事件驱 动的情况下智能体的第 Tk+1个行动等于第 Tk 个行 动,同时,迭代过程为 f t+2 = Tk+1(f t+1 ,f t+1 ) = Tk(f t,f t) (15) 令 V,U0 ,V0 ∈B( χ),Ut+1 = Tt (Ut,V),Vt+1 = Tt ( Vt, v ∗ ),δt(x)= Ut(x)-Vt(x) 。 根据收敛引理有 δt+1(x) = Ut+1(x) - Vt+1(x) = Tt Ut,v ∗ ( ) (x) - Tt Vt,Vt ( ) (x) ≤ Tt Ut,v ∗ ( ) (x) - Tt Vt,v ∗ ( ) (x) + Tt Vt,v ∗ ( ) (x) - Tt (Vt,V) (x) ≤ Gt(x) Ut(x) - Vt(x) + Ft(x) ‖v ∗ - Vt‖ + λt ( ) = Gt(x)δt(x) + Ft(x) ‖v ∗ - Vt‖ + λt ( ) ≤ Gt(x)δt(x) + Ft(x) ‖v ∗ - Vt‖ + ‖Ut - Vt‖ + λt ( ) = Gt(x)δt(x) + Ft(x)‖v ∗ - Vt‖ + λt (16) 在满足条件 1)和 2)的情况下,虽然基于事件 驱动的动作序列 T 中有相同的动作 Tk = Tk+1 ,但仍 然满足李普西斯条件,所以不会影响 Q⁃学习的收 敛,证毕。 4 仿真结果及分析 考虑一个多智能体覆盖问题,2 个智能体随机 出现在一个大小为 10×10 的格子世界中,如图 5 所 示。 每一个智能体都有上下左右 4 个行动,且观测 范围为自身周围一圈共 8 个格子,观测到的格子分 为“没走过”“走过”和“障碍物”3 个状态,分别对应 着 30、-5 和-10 的回报值,世界的边界对智能体作 为障碍物;且每一个智能体可以进行广播式通信。 在这个场景中,每一个智能体获得的是一个局部观 测,当它们进行广播通信后,对于整个世界,获得的 仍然是一个局部的观测。 但考虑到对整个世界的全 局观测需要极大的计算量,所以实验设定每一时刻 当两个智能体通信后,所获得的信息对它们而言是 一个全局观测。 智能体团队的任务为尽快走完所有的格子,即 完成对格子世界的覆盖,当走过的格子超过 90%以 上,认为此次覆盖任务成功,当智能体在 1 000 步仍 不能完成 90%的覆盖时,认为此次任务失败。 其中 定义学习率为 0.6,折扣因子为 0.2。 图 5 多智能体覆盖问题 Fig.5 The coverage problem of multi⁃agent 图 6 比较了事件驱动与传统 Q⁃学习任务成功 率,可以看出两种算法成功率一致,但是由于 Q 值 迭代次数减少,使得事件驱动 Q⁃学习的收敛速度 变慢。 图 6 事件驱动与传统 Q⁃学习的成功率 Fig.6 The success rate of event⁃triggered Q and classical Q 图 7 说明了联合触发函数与算法收敛速度的关 系,可以看出联合触发函数选取越小,算法收敛性越 慢。 因为联合触发函数越小,事件触发的次数就越 少,从而导致 Q 值迭代次数减少,收敛速度变慢。 图 7 联合触发函数与收敛速度 Fig. 7 The joint event⁃triggered function and conver⁃ gence speed 在学习过程中,智能体团队在每一步需要遍历 Q 值数量为(3 8×4) 2≈2 29.3次,由表 1 可以看出,随 着学习步数的增加,事件驱动将大量减小 Q 值的遍 历次数,继而减少计算资源占用,相比较传统的 Q⁃ 学习存在明显的优势。 ·86· 智 能 系 统 学 报 第 12 卷