正在加载图片...
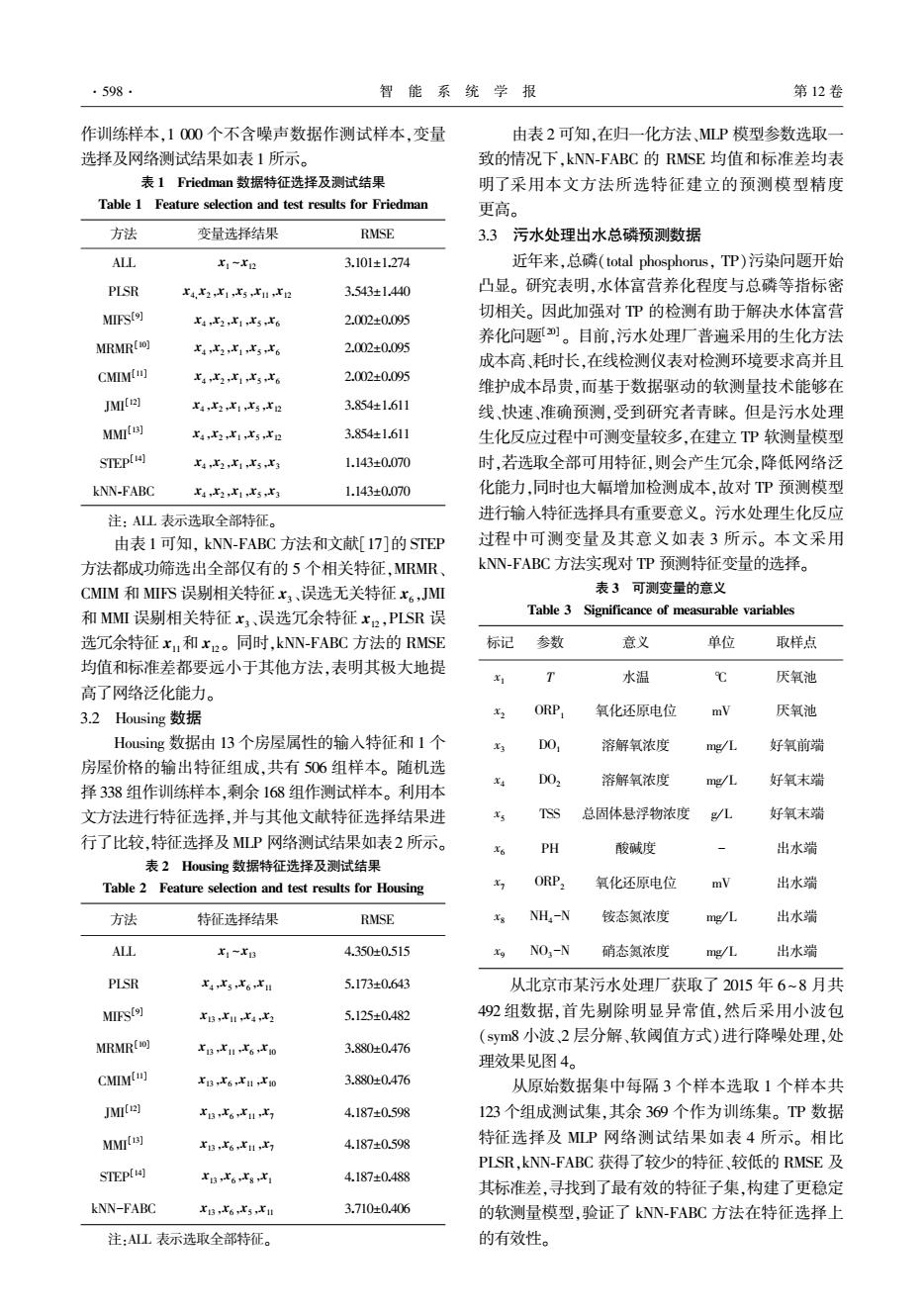
·598 智能系统学报 第12卷 作训练样本,1000个不含噪声数据作测试样本,变量 由表2可知,在归一化方法MP模型参数选取一 选择及网络测试结果如表1所示。 致的情况下,kNN-FABC的RMSE均值和标准差均表 表1 Friedman数据特征选择及测试结果 明了采用本文方法所选特征建立的预测模型精度 Table 1 Feature selection and test results for Friedman 更高。 方法 变量选择结果 RMSE 33污水处理出水总磷预测数据 ALL x1-r2 3.101±1.274 近年来,总磷(total phosphorus,TP)污染问题开始 PLSR r4,r2,r1,x5,r11,r2 3.543±1.440 凸显。研究表明,水体富营养化程度与总磷等指标密 MIFS(] x4,x2,r1,x5,r6 2.002±0.095 切相关。因此加强对P的检测有助于解决水体富营 养化问题。目前,污水处理厂普遍采用的生化方法 MRMR(H0] r4r2,x1x56 2.002±0.095 成本高、耗时长,在线检测仪表对检测环境要求高并且 CMIMI] x4,x2,1,x5x6 2.002±0.095 维护成本昂贵,而基于数据驱动的软测量技术能够在 JMIt2) xaxz:x1X5,XR 3.854±1.611 线、快速、准确预测,受到研究者青睐。但是污水处理 MM因 X,X2x1x5XR 3.854±1.611 生化反应过程中可测变量较多,在建立TP软测量模型 STEP(41 X4x2x1x5X3 1.143±0.070 时,若选取全部可用特征,则会产生冗余,降低网络泛 kNN-FABC 4,x2,x1,x5r3 1.143±0.070 化能力,同时也大幅增加检测成本,故对P预测模型 注:ALL表示选取全部特征。 进行输入特征选择具有重要意义。污水处理生化反应 由表1可知,kNN-FABC方法和文献[I7]的STEP 过程中可测变量及其意义如表3所示。本文采用 方法都成功筛选出全部仅有的5个相关特征,MRMR、 kNN-FABC方法实现对TP预测特征变量的选择。 CMM和MFS误别相关特征x3、误选无关特征x6,JM 表3可测变量的意义 和MMI误剔相关特征x3、误选冗余特征x2,PISR误 Table 3 Significance of measurable variables 选冗余特征x,和x2。同时,kNN-FABC方法的RMSE 标记 参数 意义 单位 取样点 均值和标准差都要远小于其他方法,表明其极大地提 T 水温 ℃ 厌氧池 高了网络泛化能力。 3.2 Housing数据 ORP, 氧化还原电位 mV 厌氧池 Housing数据由13个房屋属性的输入特征和1个 D01 溶解氧浓度 mg/L 好氧前端 房屋价格的输出特征组成,共有506组样本。随机选 D02 溶解氧浓度 mg/L 好氧末端 择338组作训练样本,剩余168组作测试样本。利用本 文方法进行特征选择,并与其他文献特征选择结果进 TSS 总固体悬浮物浓度 g/L 好氧末端 行了比较,特征选择及MLP网络测试结果如表2所示。 PH 酸碱度 出水端 表2 Housing数据特征选择及测试结果 Table 2 Feature selection and test results for Housing ORP, 氧化还原电位 mV 出水端 方法 特征选择结果 RMSE NH,-N 铵态氮浓度 mg/L 出水端 ALL x1-XB 4.350±0.515 NO-N 硝态氮浓度 mg/L 出水端 PLSR XaxsX6x 5.173±0.643 从北京市某污水处理厂获取了2015年6~8月共 MIFS(] xB,x1l,r4,x2 5.125±0.482 492组数据,首先剔除明显异常值,然后采用小波包 MRMR(0) (sym8小波2层分解、软阈值方式)进行降噪处理,处 XB6X10 3.880±0.476 理效果见图4。 CMIMI r13r6,r1r0 3.880±0.476 从原始数据集中每隔3个样本选取1个样本共 JMIt2) XBX6 4.187±0.598 123个组成测试集,其余369个作为训练集。TP数据 MM周 riB,t6,ri1,x 4.187±0.598 特征选择及MP网络测试结果如表4所示。相比 PLSR,kNN-FABC获得了较少的特征、较低的RMSE及 STEP[14] XBX6x8x1 4.187±0.488 其标准差,寻找到了最有效的特征子集,构建了更稳定 kNN-FABC XB,X6X5 3.710±0.406 的软测量模型,验证了kNN-FABC方法在特征选择上 注:ALL表示选取全部特征。 的有效性。作训练样本,1 000 个不含噪声数据作测试样本,变量 选择及网络测试结果如表 1 所示。 表 1 Friedman 数据特征选择及测试结果 Table 1 Feature selection and test results for Friedman 方法 变量选择结果 RMSE ALL x1 ~x12 3.101±1.274 PLSR x4,x2,x1,x5,x11,x12 3.543±1.440 MIFS [9] x4,x2,x1,x5,x6 2.002±0.095 MRMR [10] x4,x2,x1,x5,x6 2.002±0.095 CMIM [11] x4,x2,x1,x5,x6 2.002±0.095 JMI [12] x4,x2,x1,x5,x12 3.854±1.611 MMI [13] x4,x2,x1,x5,x12 3.854±1.611 STEP [14] x4,x2,x1,x5,x3 1.143±0.070 kNN⁃FABC x4,x2,x1,x5,x3 1.143±0.070 注: ALL 表示选取全部特征。 由表 1 可知, kNN⁃FABC 方法和文献[17]的 STEP 方法都成功筛选出全部仅有的 5 个相关特征,MRMR、 CMIM 和 MIFS 误剔相关特征 x3、误选无关特征 x6,JMI 和 MMI 误剔相关特征 x3、误选冗余特征 x12,PLSR 误 选冗余特征 x11和 x12。 同时,kNN⁃FABC 方法的 RMSE 均值和标准差都要远小于其他方法,表明其极大地提 高了网络泛化能力。 3.2 Housing 数据 Housing 数据由 13 个房屋属性的输入特征和 1 个 房屋价格的输出特征组成,共有 506 组样本。 随机选 择 338 组作训练样本,剩余 168 组作测试样本。 利用本 文方法进行特征选择,并与其他文献特征选择结果进 行了比较,特征选择及 MLP 网络测试结果如表2 所示。 表 2 Housing 数据特征选择及测试结果 Table 2 Feature selection and test results for Housing 方法 特征选择结果 RMSE ALL x1 ~x13 4.350±0.515 PLSR x4,x5,x6,x11 5.173±0.643 MIFS [9] x13,x11,x4,x2 5.125±0.482 MRMR [10] x13,x11,x6,x10 3.880±0.476 CMIM [11] x13,x6,x11,x10 3.880±0.476 JMI [12] x13,x6,x11,x7 4.187±0.598 MMI [13] x13,x6,x11,x7 4.187±0.598 STEP [14] x13,x6,x8,x1 4.187±0.488 kNN-FABC x13,x6,x5,x11 3.710±0.406 注:ALL 表示选取全部特征。 由表 2 可知,在归一化方法、MLP 模型参数选取一 致的情况下,kNN⁃FABC 的 RMSE 均值和标准差均表 明了采用本文方法所选特征建立的预测模型精度 更高。 3.3 污水处理出水总磷预测数据 近年来,总磷(total phosphorus, TP)污染问题开始 凸显。 研究表明,水体富营养化程度与总磷等指标密 切相关。 因此加强对 TP 的检测有助于解决水体富营 养化问题[20] 。 目前,污水处理厂普遍采用的生化方法 成本高、耗时长,在线检测仪表对检测环境要求高并且 维护成本昂贵,而基于数据驱动的软测量技术能够在 线、快速、准确预测,受到研究者青睐。 但是污水处理 生化反应过程中可测变量较多,在建立 TP 软测量模型 时,若选取全部可用特征,则会产生冗余,降低网络泛 化能力,同时也大幅增加检测成本,故对 TP 预测模型 进行输入特征选择具有重要意义。 污水处理生化反应 过程中可测变量及其意义如表 3 所示。 本文采用 kNN⁃FABC 方法实现对 TP 预测特征变量的选择。 表 3 可测变量的意义 Table 3 Significance of measurable variables 标记 参数 意义 单位 取样点 x1 T 水温 ℃ 厌氧池 x2 ORP1 氧化还原电位 mV 厌氧池 x3 DO1 溶解氧浓度 mg / L 好氧前端 x4 DO2 溶解氧浓度 mg / L 好氧末端 x5 TSS 总固体悬浮物浓度 g / L 好氧末端 x6 PH 酸碱度 - 出水端 x7 ORP2 氧化还原电位 mV 出水端 x8 NH4 -N 铵态氮浓度 mg / L 出水端 x9 NO3 -N 硝态氮浓度 mg / L 出水端 从北京市某污水处理厂获取了 2015 年 6~8 月共 492 组数据,首先剔除明显异常值,然后采用小波包 (sym8 小波、2 层分解、软阈值方式)进行降噪处理,处 理效果见图 4。 从原始数据集中每隔 3 个样本选取 1 个样本共 123 个组成测试集,其余 369 个作为训练集。 TP 数据 特征选择及 MLP 网络测试结果如表 4 所示。 相比 PLSR,kNN⁃FABC 获得了较少的特征、较低的 RMSE 及 其标准差,寻找到了最有效的特征子集,构建了更稳定 的软测量模型,验证了 kNN⁃FABC 方法在特征选择上 的有效性。 ·598· 智 能 系 统 学 报 第 12 卷