正在加载图片...
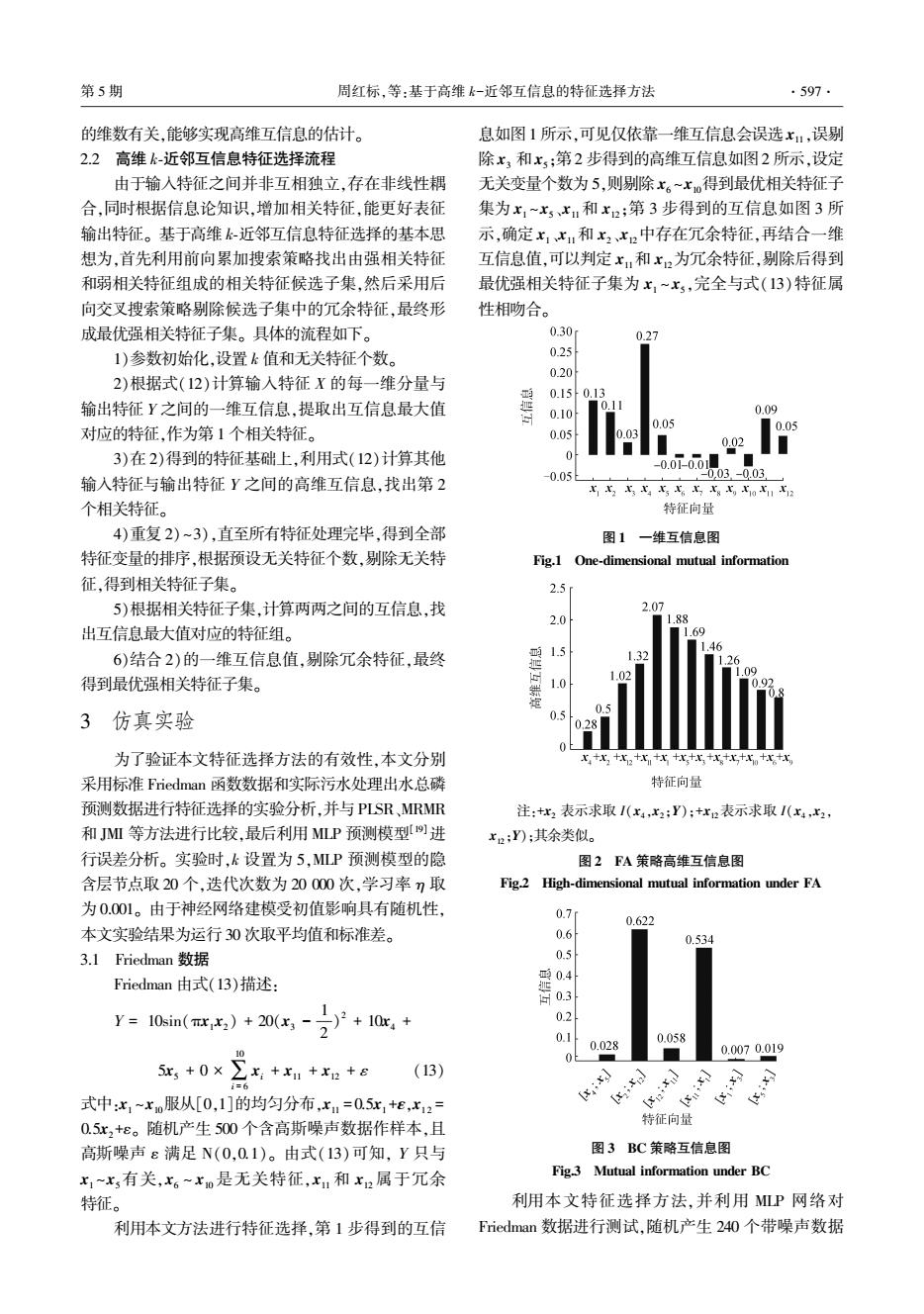
第5期 周红标,等:基于高维k-近邻互信息的特征选择方法 .597. 的维数有关,能够实现高维互信息的估计。 息如图1所示,可见仅依靠一维互信息会误选x1,误别 2.2高维k-近邻互信息特征选择流程 除x,和x:第2步得到的高维互信息如图2所示,设定 由于输入特征之间并非互相独立,存在非线性耦 无关变量个数为5,则剔除x。~x。得到最优相关特征子 合,同时根据信息论知识,增加相关特征,能更好表征 集为x,~xx,和x2;第3步得到的互信息如图3所 输出特征。基于高维k-近邻互信息特征选择的基本思 示,确定x1x,和x2x2中存在冗余特征,再结合一维 想为,首先利用前向累加搜索策略找出由强相关特征 互信息值,可以判定x,和x2为冗余特征,别除后得到 和弱相关特征组成的相关特征候选子集,然后采用后 最优强相关特征子集为x,~x,完全与式(13)特征属 向交叉搜索策略剔除候选子集中的冗余特征,最终形 性相吻合。 成最优强相关特征子集。具体的流程如下。 0.30 0.27 1)参数初始化,设置k值和无关特征个数。 0.25 0.20 2)根据式(12)计算输入特征X的每一维分量与 0.15 0.13 输出特征Y之间的一维互信息,提取出互信息最大值 0.10 0.09 0.05 对应的特征,作为第1个相关特征。 0.05 0.05 3)在2)得到的特征基础上,利用式(12)计算其他 -0.0i-00 0052 0.03.-0.03 输入特征与输出特征Y之间的高维互信息,找出第2 xx x5o112 个相关特征。 特征向量 4)重复2)~3),直至所有特征处理完毕,得到全部 图1一维互信息图 特征变量的排序,根据预设无关特征个数,剔除无关特 Fig.1 One-dimensional mutual information 征,得到相关特征子集。 2.5 5)根据相关特征子集,计算两两之间的互信息,找 2.07 2.0 ■1.88 出互信息最大值对应的特征组。 ■1.69 1.5 1.46 6)结合2)的一维互信息值,剔除冗余特征,最终 1.32 16 得到最优强相关特征子集。 1.02 1.0 0 3仿真实验 0.5 0.28 为了验证本文特征选择方法的有效性,本文分别 x比+比2+r,+x+r+xx+比+x+xtx 采用标准Friedman函数数据和实际污水处理出水总磷 特征向量 预测数据进行特征选择的实验分析,并与PLSR,MRMR 注:+2表示求取I(x4,x2;Y):+x2表示求取I(x4,x2, 和MI等方法进行比较,最后利用MLP预测模型进 x2;Y);其余类似。 行误差分析。实验时,k设置为5,MLP预测模型的隐 图2FA策略高维互信息图 含层节点取20个,迭代次数为20000次,学习率7取 Fig.2 High-dimensional mutual information under FA 为0.001。由于神经网络建模受初值影响具有随机性, 0.7d 0.622 本文实验结果为运行30次取平均值和标准差。 0.6 0.534 3.1 Friedman数据 0.5 Friedman由式(13)描述: 0.4 问03 y=10sin(mxx,)+20(x3-7)°+10c+ 0.2 0.1 0.028 0.058 5x,+0×∑x+x,+x2+e 0.0070.019 (13) i=6 式中:x1~xo服从[0,1]的均匀分布,x1=0.5x,+e,x12= [x:xj 0.5x2+ε。随机产生500个含高斯噪声数据作样本,且 特征向量 高斯噪声ε满足N(0,0.1)。由式(13)可知,Y只与 图3BC策略互信息图 x1~x有关,x6~xo是无关特征,x1和x2属于冗余 Fig.3 Mutual information under BC 特征。 利用本文特征选择方法,并利用MP网络对 利用本文方法进行特征选择,第1步得到的互信 Friedman数据进行测试,随机产生240个带噪声数据的维数有关,能够实现高维互信息的估计。 2.2 高维 k⁃近邻互信息特征选择流程 由于输入特征之间并非互相独立,存在非线性耦 合,同时根据信息论知识,增加相关特征,能更好表征 输出特征。 基于高维 k⁃近邻互信息特征选择的基本思 想为,首先利用前向累加搜索策略找出由强相关特征 和弱相关特征组成的相关特征候选子集,然后采用后 向交叉搜索策略剔除候选子集中的冗余特征,最终形 成最优强相关特征子集。 具体的流程如下。 1)参数初始化,设置 k 值和无关特征个数。 2)根据式(12)计算输入特征 X 的每一维分量与 输出特征 Y 之间的一维互信息,提取出互信息最大值 对应的特征,作为第 1 个相关特征。 3)在 2)得到的特征基础上,利用式(12)计算其他 输入特征与输出特征 Y 之间的高维互信息,找出第 2 个相关特征。 4)重复 2) ~3),直至所有特征处理完毕,得到全部 特征变量的排序,根据预设无关特征个数,剔除无关特 征,得到相关特征子集。 5)根据相关特征子集,计算两两之间的互信息,找 出互信息最大值对应的特征组。 6)结合 2)的一维互信息值,剔除冗余特征,最终 得到最优强相关特征子集。 3 仿真实验 为了验证本文特征选择方法的有效性,本文分别 采用标准 Friedman 函数数据和实际污水处理出水总磷 预测数据进行特征选择的实验分析,并与 PLSR、MRMR 和 JMI 等方法进行比较,最后利用 MLP 预测模型[19]进 行误差分析。 实验时,k 设置为 5,MLP 预测模型的隐 含层节点取 20 个,迭代次数为 20 000 次,学习率 η 取 为 0.001。 由于神经网络建模受初值影响具有随机性, 本文实验结果为运行 30 次取平均值和标准差。 3.1 Friedman 数据 Friedman 由式(13)描述: Y = 10sin(πx1x2) + 20(x3 - 1 2 ) 2 + 10x4 + 5x5 + 0 × ∑ 10 i = 6 xi + x11 + x12 + ε (13) 式中:x1 ~x10服从[0,1]的均匀分布,x11 = 0.5x1 +ε,x12 = 0.5x2 +ε。 随机产生 500 个含高斯噪声数据作样本,且 高斯噪声 ε 满足 N(0,0.1)。 由式(13)可知, Y 只与 x1 ~x5有关,x6 ~ x10 是无关特征,x11 和 x12 属于冗余 特征。 利用本文方法进行特征选择,第 1 步得到的互信 息如图1 所示,可见仅依靠一维互信息会误选 x11,误剔 除 x3 和x5;第2 步得到的高维互信息如图2 所示,设定 无关变量个数为 5,则剔除 x6 ~x10得到最优相关特征子 集为 x1 ~x5、x11和 x12;第 3 步得到的互信息如图 3 所 示,确定 x1、x11和 x2、x12中存在冗余特征,再结合一维 互信息值,可以判定 x11和 x12为冗余特征,剔除后得到 最优强相关特征子集为 x1 ~ x5,完全与式(13)特征属 性相吻合。 图 1 一维互信息图 Fig.1 One⁃dimensional mutual information 注:+x2 表示求取 I(x4,x2;Y);+x12表示求取 I(x4,x2, x12;Y);其余类似。 图 2 FA 策略高维互信息图 Fig.2 High⁃dimensional mutual information under FA 图 3 BC 策略互信息图 Fig.3 Mutual information under BC 利用本文特征选择方法,并利用 MLP 网络对 Friedman 数据进行测试,随机产生 240 个带噪声数据 第 5 期 周红标,等:基于高维 k-近邻互信息的特征选择方法 ·597·