正在加载图片...
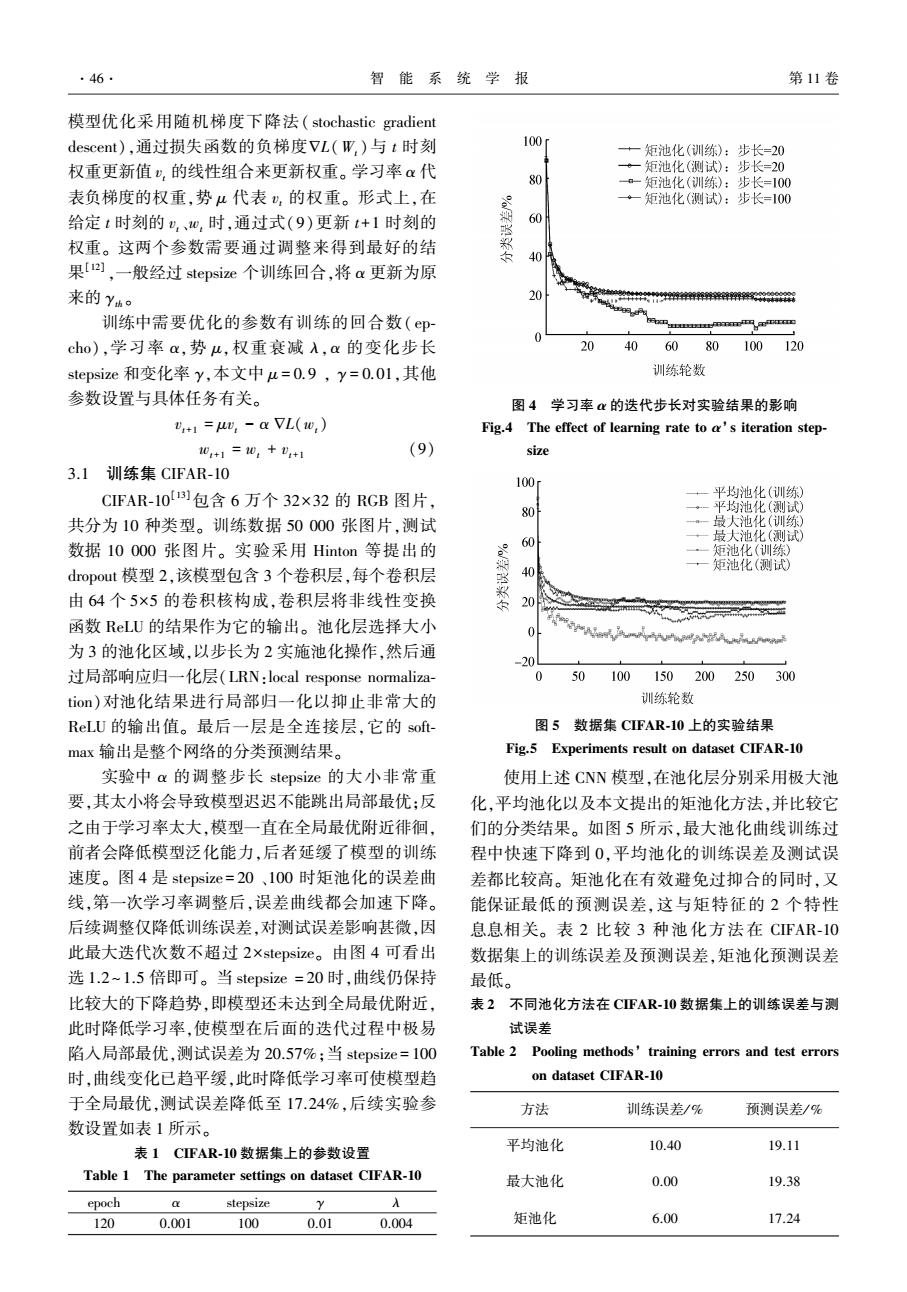
·46. 智能系统学报 第11卷 模型优化采用随机梯度下降法(stochastic gradient descent),通过损失函数的负梯度VL(W,)与t时刻 100 +一矩池化(训练):步长=20 权重更新值),的线性组合来更新权重。学习率α代 ·一矩池化(测试):步长=20 80 a-矩池化(训练):步长=100 表负梯度的权重,势4代表,的权重。形式上,在 矩池化(测试):步长=100 给定t时刻的,、心,时,通过式(9)更新t+1时刻的 60 权重。这两个参数需要通过调整来得到最好的结 40 果[],一般经过stepsize个训练回合,将a更新为原 来的Yh。 20 4449444年年44件464009 训练中需要优化的参数有训练的回合数(ep mm cho),学习率,势u,权重衰减入,a的变化步长 20 406080100120 stepsize和变化率y,本文中u=0.9,y=0.0l,其他 训练轮数 参数设置与具体任务有关。 图4学习率心的迭代步长对实验结果的影响 v+1=,-aVL(w,) Fig.4 The effect of learning rate to a's iteration step- 0+1=0,+D+i (9) size 3.1圳练集CIFAR-10 100 CIFAR-10)包含6万个32×32的RGB图片, ·一平均池化(训练) 80 平均池化(测试) 共分为10种类型。训练数据50000张图片,测试 最大池化(训练) 60 最大池化(测试) 数据10000张图片。实验采用Hinton等提出的 矩池化(训练) dropout模型2,该模型包含3个卷积层,每个卷积层 40 一矩池化(测试 由64个5×5的卷积核构成,卷积层将非线性变换 彩 函数RLU的结果作为它的输出。池化层选择大小 2D-一A 0 为3的池化区域,以步长为2实施池化操作,然后通 20 过局部响应归一化层(LRN:local response normaliza- 0 50 100150200250300 tion)对池化结果进行局部归一化以抑止非常大的 训练轮数 ReLU的输出值。最后一层是全连接层,它的sof 图5数据集CIFAR-10上的实验结果 max输出是整个网络的分类预测结果。 Fig.5 Experiments result on dataset CIFAR-10 实验中a的调整步长stepsize的大小非常重 使用上述CNN模型,在池化层分别采用极大池 要,其太小将会导致模型迟迟不能跳出局部最优;反 化,平均池化以及本文提出的矩池化方法,并比较它 之由于学习率太大,模型一直在全局最优附近徘徊, 们的分类结果。如图5所示,最大池化曲线训练过 前者会降低模型泛化能力,后者延缓了模型的训练 程中快速下降到0,平均池化的训练误差及测试误 速度。图4是stepsize=20、100时矩池化的误差曲 差都比较高。矩池化在有效避免过抑合的同时,又 线,第一次学习率调整后,误差曲线都会加速下降。 能保证最低的预测误差,这与矩特征的2个特性 后续调整仅降低训练误差,对测试误差影响甚微,因 息息相关。表2比较3种池化方法在CIFAR-10 此最大迭代次数不超过2×stepsize。由图4可看出 数据集上的训练误差及预测误差,矩池化预测误差 选1.2~1.5倍即可。当stepsize=20时,曲线仍保持 最低。 比较大的下降趋势,即模型还未达到全局最优附近, 表2不同池化方法在CFAR-10数据集上的训练误差与测 此时降低学习率,使模型在后面的迭代过程中极易 试误差 陷入局部最优,测试误差为20.57%:当stepsize=100 Table 2 Pooling methods'training errors and test errors 时,曲线变化已趋平缓,此时降低学习率可使模型趋 on dataset CIFAR-10 于全局最优,测试误差降低至17.24%,后续实验参 方法 训练误差/% 预测误差/% 数设置如表1所示。 表1CFAR-10数据集上的参数设置 平均池化 10.40 19.11 Table 1 The parameter settings on dataset CIFAR-10 最大池化 0.00 19.38 epoch stepsize A 120 0.001 100 0.01 0.004 矩池化 6.00 17.24模型优化采用随机梯度下降法( stochastic gradient descent),通过损失函数的负梯度ÑL(Wt )与 t 时刻 权重更新值 vt 的线性组合来更新权重。 学习率 α 代 表负梯度的权重,势 μ 代表 vt 的权重。 形式上,在 给定 t 时刻的 vt、wt 时,通过式(9)更新 t+1 时刻的 权重。 这两个参数需要通过调整来得到最好的结 果[12] ,一般经过 stepsize 个训练回合,将 α 更新为原 来的 γth 。 训练中需要优化的参数有训练的回合数( ep⁃ cho),学习率 α,势 μ,权重衰减 λ,α 的变化步长 stepsize 和变化率 γ,本文中 μ = 0.9 , γ = 0.01,其他 参数设置与具体任务有关。 vt+1 = μvt - α ÑL(wt) wt+1 = wt + vt+1 (9) 3.1 训练集 CIFAR⁃10 CIFAR⁃10 [13]包含 6 万个 32×32 的 RGB 图片, 共分为 10 种类型。 训练数据 50 000 张图片,测试 数据 10 000 张图片。 实验采用 Hinton 等提出的 dropout 模型 2,该模型包含 3 个卷积层,每个卷积层 由 64 个 5×5 的卷积核构成,卷积层将非线性变换 函数 ReLU 的结果作为它的输出。 池化层选择大小 为 3 的池化区域,以步长为 2 实施池化操作,然后通 过局部响应归一化层(LRN:local response normaliza⁃ tion)对池化结果进行局部归一化以抑止非常大的 ReLU 的输出值。 最后一层是全连接层,它的 soft⁃ max 输出是整个网络的分类预测结果。 实验中 α 的调整步长 stepsize 的大小非常重 要,其太小将会导致模型迟迟不能跳出局部最优;反 之由于学习率太大,模型一直在全局最优附近徘徊, 前者会降低模型泛化能力,后者延缓了模型的训练 速度。 图 4 是 stepsize = 20 、100 时矩池化的误差曲 线,第一次学习率调整后,误差曲线都会加速下降。 后续调整仅降低训练误差,对测试误差影响甚微,因 此最大迭代次数不超过 2×stepsize。 由图 4 可看出 选 1.2~1.5 倍即可。 当 stepsize = 20 时,曲线仍保持 比较大的下降趋势,即模型还未达到全局最优附近, 此时降低学习率,使模型在后面的迭代过程中极易 陷入局部最优,测试误差为 20.57%;当 stepsize = 100 时,曲线变化已趋平缓,此时降低学习率可使模型趋 于全局最优,测试误差降低至 17.24%,后续实验参 数设置如表 1 所示。 表 1 CIFAR⁃10 数据集上的参数设置 Table 1 The parameter settings on dataset CIFAR⁃10 epoch α stepsize γ λ 120 0.001 100 0.01 0.004 图 4 学习率 α 的迭代步长对实验结果的影响 Fig.4 The effect of learning rate to α’ s iteration step⁃ size 图 5 数据集 CIFAR⁃10 上的实验结果 Fig.5 Experiments result on dataset CIFAR⁃10 使用上述 CNN 模型,在池化层分别采用极大池 化,平均池化以及本文提出的矩池化方法,并比较它 们的分类结果。 如图 5 所示,最大池化曲线训练过 程中快速下降到 0,平均池化的训练误差及测试误 差都比较高。 矩池化在有效避免过抑合的同时,又 能保证最低的预测误差,这与矩特征的 2 个特性 息息相关。 表 2 比较 3 种池化方法在 CIFAR⁃10 数据集上的训练误差及预测误差,矩池化预测误差 最低。 表 2 不同池化方法在 CIFAR⁃10 数据集上的训练误差与测 试误差 Table 2 Pooling methods’ training errors and test errors on dataset CIFAR⁃10 方法 训练误差/ % 预测误差/ % 平均池化 10.40 19.11 最大池化 0.00 19.38 矩池化 6.00 17.24 ·46· 智 能 系 统 学 报 第 11 卷