正在加载图片...
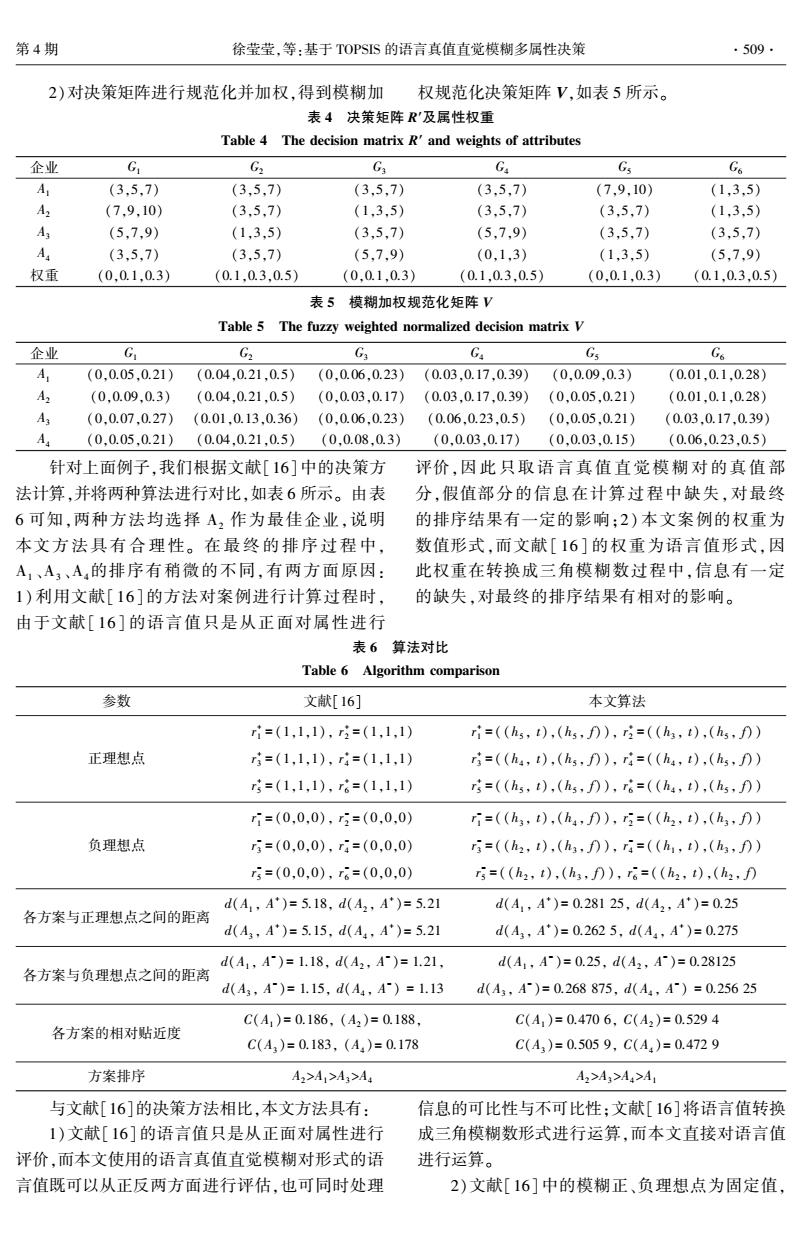
第4期 徐莹莹,等:基于TOPSIS的语言真值直觉模糊多属性决策 ·509· 2)对决策矩阵进行规范化并加权,得到模糊加 权规范化决策矩阵V,如表5所示。 表4决策矩阵R'及属性权重 Table 4 The decision matrix R'and weights of attributes 企业 G G2 G3 G Gs Go A (3.5.7) (3,5.7) (3.5.7) (3.5.7) (7,9,10) (1,3,5) A2 (7.9.10) (3,5,7) (1,3,5) (3,5.7) (3.5,7) (1,3,5) A (5,7,9) (1,3,5) (3,5,7) (5,7,9) (3,5,7) (3,5,7) A (3,5,7) (3,5,7) (5,7,9) (0,1,3) (1,3,5) (5,7,9) 权重 (0,0.1.0.3) (0.1.0.3.0.5) (0,0.1,0.3) (0.1.0.3,0.5) (0.0.1,0.3) (0.1,0.3,0.5) 表5模糊加权规范化矩阵V Table 5 The fuzzy weighted normalized decision matrix V 企业 G G2 Gs G Gs Go A (0.0.05.0.21) (0.04.0.21.0.5) (0.0.06.0.23)(0.03.0.17.0.39) (0.0.09.0.3) (0.01.0.1.0.28) A2 (0.0.09.0.3) (0.04.0.21.0.5) (0.0.03,0.17) (0.03.0.17.0.39) (0.0.05.0.21) (0.01.0.1,0.28) (0.0.07.0.27) (0.01.0.13.0.36) (0.0.06.0.23) (0.06.0.23.0.5) (0.0.05.0.21) (0.03.0.17.0.39 A (0,0.05,0.21) (0.04,0.21,0.5) (0,0.08,0.3) (0,0.03,0.17) (0,0.03,0.15) (0.06,0.23,0.5) 针对上面例子,我们根据文献[16]中的决策方 评价,因此只取语言真值直觉模糊对的真值部 法计算,并将两种算法进行对比,如表6所示。由表 分,假值部分的信息在计算过程中缺失,对最终 6可知,两种方法均选择A,作为最佳企业,说明 的排序结果有一定的影响:2)本文案例的权重为 本文方法具有合理性。在最终的排序过程中, 数值形式,而文献[16]的权重为语言值形式,因 A1、A,、A的排序有稍微的不同,有两方面原因: 此权重在转换成三角模糊数过程中,信息有一定 1)利用文献[16]的方法对案例进行计算过程时, 的缺失,对最终的排序结果有相对的影响。 由于文献[16]的语言值只是从正面对属性进行 表6算法对比 Table 6 Algorithm comparison 参数 文献[16] 本文算法 =(1,1,1),=(1,1,1) ri=((h5,t),(h5,fD),ri=((h,t),(h,f月) 正理想点 =(1,1,1),r4=(1,1,1) r=((h4,t),(h5,fD),ri=((h4,t),(h,fD) r=(1,1,1),r6=(1,1,1) =(hs,t),(h,fD),T6=((h4,t),(h5,f)) ri=(0,0,0),=(0,0,0) ri=((h3,t),(h,fD),5=(h2,t),(h3,f)) 负理想点 3=(0,0,0),r4=(0,0,0) i=((h2,t),(h3,f)),r4=(h1,t),(h3,f)) r5=(0,0,0),t6=(0,0,0) i=(h2,t),(h,fD),r6=((h2,t),(h2,fD d(A,A)=5.18,d(A2,A)=5.21 d(4,A)=0.28125,d(A2,A)=0.25 各方案与正理想点之间的距离 d(A3,A)=5.15,d(A4,A)=5.21 d(A3,A)=0.2625,d(A4,A)=0.275 d(A1,A)=1.18,d(A2,A)=1.21, d(A,A)=0.25,d(A2,A)=0.28125 各方案与负理想点之间的距离 d(A3,A)=1.15,d(A4,A)=1.13 d(A3,A)=0.268875,d(A4,A)=0.25625 C(A1)=0.186,(A2)=0.188, C(A1)=0.4706,C(A2)=0.5294 各方案的相对贴近度 C(A3)=0.183,(A4)=0.178 C(A)=0.5059,C(A4)=0.4729 方案排序 A2>A1>A3>A4 A2>A>A>A 与文献[16]的决策方法相比,本文方法具有: 信息的可比性与不可比性;文献[16]将语言值转换 1)文献[16]的语言值只是从正面对属性进行 成三角模糊数形式进行运算,而本文直接对语言值 评价,而本文使用的语言真值直觉模糊对形式的语 进行运算。 言值既可以从正反两方面进行评估,也可同时处理 2)文献[16]中的模糊正、负理想点为固定值,2)对决策矩阵进行规范化并加权,得到模糊加 权规范化决策矩阵 V,如表 5 所示。 表 4 决策矩阵 R′及属性权重 Table 4 The decision matrix R′ and weights of attributes 企业 G1 G2 G3 G4 G5 G6 A1 (3,5,7) (3,5,7) (3,5,7) (3,5,7) (7,9,10) (1,3,5) A2 (7,9,10) (3,5,7) (1,3,5) (3,5,7) (3,5,7) (1,3,5) A3 (5,7,9) (1,3,5) (3,5,7) (5,7,9) (3,5,7) (3,5,7) A4 (3,5,7) (3,5,7) (5,7,9) (0,1,3) (1,3,5) (5,7,9) 权重 (0,0.1,0.3) (0.1,0.3,0.5) (0,0.1,0.3) (0.1,0.3,0.5) (0,0.1,0.3) (0.1,0.3,0.5) 表 5 模糊加权规范化矩阵 V Table 5 The fuzzy weighted normalized decision matrix V 企业 G1 G2 G3 G4 G5 G6 A1 (0,0.05,0.21) (0.04,0.21,0.5) (0,0.06,0.23) (0.03,0.17,0.39) (0,0.09,0.3) (0.01,0.1,0.28) A2 (0,0.09,0.3) (0.04,0.21,0.5) (0,0.03,0.17) (0.03,0.17,0.39) (0,0.05,0.21) (0.01,0.1,0.28) A3 (0,0.07,0.27) (0.01,0.13,0.36) (0,0.06,0.23) (0.06,0.23,0.5) (0,0.05,0.21) (0.03,0.17,0.39) A4 (0,0.05,0.21) (0.04,0.21,0.5) (0,0.08,0.3) (0,0.03,0.17) (0,0.03,0.15) (0.06,0.23,0.5) 针对上面例子,我们根据文献[16]中的决策方 法计算,并将两种算法进行对比,如表 6 所示。 由表 6 可知,两种方法均选择 A2 作为最佳企业,说明 本文方 法 具 有 合 理 性。 在 最 终 的 排 序 过 程 中, A1 、A3 、A4的排序有稍微的不同,有两方面原因: 1)利用文献[ 16]的方法对案例进行计算过程时, 由于文献[ 16] 的语言值只是从正面对属性进行 评价,因 此 只 取 语 言 真 值 直 觉 模 糊 对 的 真 值 部 分,假值部分的信息在计算过程中缺失,对最终 的排序结果有一定的影响;2) 本文案例的权重为 数值形式,而文献[ 16] 的权重为语言值形式,因 此权重在转换成三角模糊数过程中,信息有一定 的缺失,对最终的排序结果有相对的影响。 表 6 算法对比 Table 6 Algorithm comparison 参数 文献[16] 本文算法 正理想点 r + 1 = (1,1,1), r + 2 = (1,1,1) r + 3 = (1,1,1), r + 4 = (1,1,1) r + 5 = (1,1,1), r + 6 = (1,1,1) r + 1 = ((h5 , t),(h5 , f)), r + 2 = ((h3 , t),(h5 , f)) r + 3 = ((h4 , t),(h5 , f)), r + 4 = ((h4 , t),(h5 , f)) r + 5 = ((h5 , t),(h5 , f)), r + 6 = ((h4 , t),(h5 , f)) 负理想点 r - 1 = (0,0,0), r - 2 = (0,0,0) r - 3 = (0,0,0), r - 4 = (0,0,0) r - 5 = (0,0,0), r - 6 = (0,0,0) r - 1 = ((h3 , t),(h4 , f)), r - 2 = ((h2 , t),(h3 , f)) r - 3 = ((h2 , t),(h3 , f)), r - 4 = ((h1 , t),(h3 , f)) r - 5 = ((h2 , t),(h3 , f)), r - 6 = ((h2 , t),(h2 , f) 各方案与正理想点之间的距离 d(A1 , A + )= 5.18, d(A2 , A + )= 5.21 d(A3 , A + )= 5.15, d(A4 , A + )= 5.21 d(A1 , A + )= 0.281 25, d(A2 , A + )= 0.25 d(A3 , A + )= 0.262 5, d(A4 , A + )= 0.275 各方案与负理想点之间的距离 d(A1 , A - )= 1.18, d(A2 , A - )= 1.21, d(A3 , A - )= 1.15, d(A4 , A - ) = 1.13 d(A1 , A - )= 0.25, d(A2 , A - )= 0.28125 d(A3 , A - )= 0.268 875, d(A4 , A - ) = 0.256 25 各方案的相对贴近度 C(A1 )= 0.186, (A2 )= 0.188, C(A3 )= 0.183, (A4 )= 0.178 C(A1 )= 0.470 6, C(A2 )= 0.529 4 C(A3 )= 0.505 9, C(A4 )= 0.472 9 方案排序 A2>A1>A3>A4 A2>A3>A4>A1 与文献[16]的决策方法相比,本文方法具有: 1)文献[16]的语言值只是从正面对属性进行 评价,而本文使用的语言真值直觉模糊对形式的语 言值既可以从正反两方面进行评估,也可同时处理 信息的可比性与不可比性;文献[16]将语言值转换 成三角模糊数形式进行运算,而本文直接对语言值 进行运算。 2)文献[16]中的模糊正、负理想点为固定值, 第 4 期 徐莹莹,等:基于 TOPSIS 的语言真值直觉模糊多属性决策 ·509·