正在加载图片...
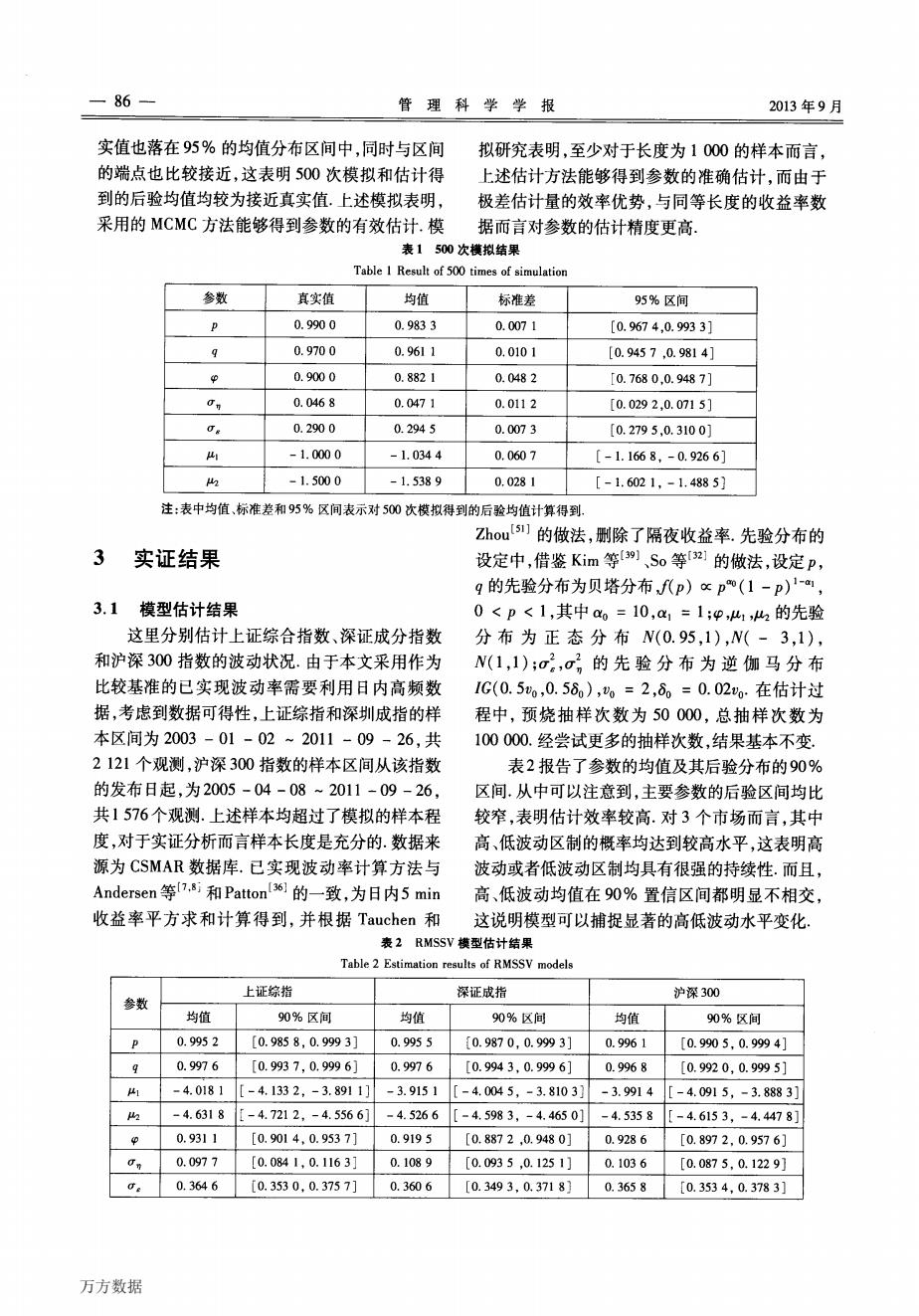
—86 管理科学学报 2013年9月 实值也落在95%的均值分布区间中,同时与区间 拟研究表明,至少对于长度为1000的样本而言, 的端,点也比较接近,这表明500次模拟和估计得 上述估计方法能够得到参数的准确估计,而由于 到的后验均值均较为接近真实值.上述模拟表明, 极差估计量的效率优势,与同等长度的收益率数 采用的MCMC方法能够得到参数的有效估计.模 据而言对参数的估计精度更高. 表1500次模拟结果 Table 1 Result of 500 times of simulation 参数 真实值 均值 标准差 95%区间 p 0.9900 0.9833 0.0071 [0.9674,0.9933] 9 0.9700 0.9611 0.0101 [0.9457,0.9814] 0.9000 0.8821 0.0482 [0.7680,0.9487] On 0.0468 0.0471 0.0112 [0.0292,0.0715] O& 0.2900 0.2945 0.0073 [0.2795,0.3100] -1.0000 -1.0344 0.0607 [-1.1668,-0.9266] 2 -1.5000 -1.5389 0.0281 [-1.6021,-1.4885】 注:表中均值、标准差和95%区间表示对500次模拟得到的后验均值计算得到, Zhou's1]的做法,删除了隔夜收益率.先验分布的 3实证结果 设定中,借鉴Kim等9,S0等]的做法,设定p, g的先验分布为贝塔分布,fp)cp(1-p)-, 3.1模型估计结果 0<p<1,其中a。=10,a1=1;p,41,h2的先验 这里分别估计上证综合指数、深证成分指数 分布为正态分布N(0.95,1),W(-3,1), 和沪深300指数的波动状况.由于本文采用作为 N(1,1);o,o,的先验分布为逆伽马分布 比较基准的已实现波动率需要利用日内高频数 1G(0.5o,0.56),=2,6=0.02vo.在估计过 据,考虑到数据可得性,上证综指和深圳成指的样 程中,预烧抽样次数为50000,总抽样次数为 本区间为2003-01-02~2011-09-26,共 100000.经尝试更多的抽样次数,结果基本不变. 2121个观测,沪深300指数的样本区间从该指数 表2报告了参数的均值及其后验分布的90% 的发布日起,为2005-04-08~2011-09-26, 区间,从中可以注意到,主要参数的后验区间均比 共1576个观测.上述样本均超过了模拟的样本程 较窄,表明估计效率较高.对3个市场而言,其中 度,对于实证分析而言样本长度是充分的.数据来 高、低波动区制的概率均达到较高水平,这表明高 源为CSMAR数据库.已实现波动率计算方法与 波动或者低波动区制均具有很强的持续性.而且, Andersen等7,si和Patton36]的一致,为日内5min 高、低波动均值在90%置信区间都明显不相交, 收益率平方求和计算得到,并根据Tauchen和 这说明模型可以捕捉显著的高低波动水平变化 表2 RMSSV模型估计结果 Table 2 Estimation results of RMSSV models 上证综指 深证成指 沪深300 参数 均值 90%区间 均值 90%区间 均值 90%区间 0.9952 [0.9858,0.9993] 0.9955 [0.9870,0.9993] 0.9961 [0.9905,0.9994] 9 0.9976 「0.9937,0.9996 0.9976 [0.9943,0.9996] 0.9968 [0.9920,0.9995] 华 -4.0181 [-4.1332,-3.8911] -3.9151 [-4.0045,-3.8103] -3.9914 [-4.0915,-3.8883] % -4.6318 [-4.7212,-4.5566] -4.5266 [-4.5983,-4.46501 -4.5358 [-4.6153,-4.44781 p 0.9311 [0.9014,0.9537] 0.9195 [0.8872,0.9480] 0.9286 [0.8972.0.9576] 0看 0.0977 [0.0841,0.1163] 0.1089 [0.0935,0.1251] 0.1036 [0.0875,0.1229] 0.3646 [0.3530.0.3757] 0.3606 [0.3493,0.3718 0.3658 [0.3534,0.3783] 万方数据一86~ 管理科学学报 2013年9月 实值也落在95%的均值分布区间中,同时与区间 的端点也比较接近,这表明500次模拟和估计得 到的后验均值均较为接近真实值.上述模拟表明, 拟研究表明,至少对于长度为1 000的样本而言, 上述估计方法能够得到参数的准确估计,而由于 极差估计量的效率优势,与同等长度的收益率数 采用的MCMC方法能够得到参数的有效估计.模 据而言对参数的估计精度更高. 表1 500次模拟结果 Table l Result of 500 times of simulation 参数 真实值 均值 标准差 95%区间 p 0.990 0 0.983 3 O.007 1 [0.967 4,0.993 3] g 0.970 0 0.961 1 0.010 1 [0.945 7,0.981 4] ∞ 0.900 O 0.882 l 0.048 2 [0.768 0,0.948 7] 盯" 0.046 8 0.047 1 0.011 2 [0.029 2,0.071 5] 盯s 0.290 O 0.294 5 O.007 3 [0.279 5,0.310 0] p1 一1.000 0 —1.034 4 0.060 7 [一1.166 8,一0.926 6] № 一1.500 O 一1.538 9 0.028 l [一1.602 1,一1.488 5] 注:表中均值、标准差和95%区间表示对500次模拟得到的后验均值计算得到 3 实证结果 3.1 模型估计结果 这里分别估计上证综合指数、深证成分指数 和沪深300指数的波动状况.由于本文采用作为 比较基准的已实现波动率需要利用日内高频数 据,考虑到数据可得性,上证综指和深圳成指的样 本区间为2003—01—02—2011—09—26,共 2 121个观测,沪深300指数的样本区间从该指数 的发布日起,为2005—04—08~2011—09—26, 共1 576个观测.上述样本均超过了模拟的样本程 度,对于实证分析而言样本长度是充分的.数据来 源为CSMAR数据库.已实现波动率计算方法与 Zhou∞川的做法,删除了隔夜收益率.先验分布的 设定中,借鉴Kim等口9|、so等口23的做法,设定P, q的先验分布为贝塔分布以P)OC P咖(1一P)1-aI, 0<P<1,其中ao=10,O/1=1;妒,肛l,肛2的先验 分布为正态分布N(0.95,1),N(一3,1), N(1,1);盯:,盯i的先验分布为逆伽马分布 IG(O.5v。,0.5氏),秽。=2,氏=0.02vo.在估计过 程中,预烧抽样次数为50 000,总抽样次数为 100 000.经尝试更多的抽样次数,结果基本不变. 表2报告了参数的均值及其后验分布的90% 区间.从中可以注意到,主要参数的后验区间均比 较窄,表明估计效率较高.对3个市场而言,其中 高、低波动区制的概率均达到较高水平,这表明高 波动或者低波动区制均具有很强的持续性.而且, Andersen等‘7’81 Patton‘36 3的一致,为Et内5 min 高、低波动均值在90%置信区间都明显不相交, 收益率平方求和计算得到,并根据Tauchen和 这说明模型可以捕捉显著的高低波动水平变化. 表2 RMSSV模型估计结果 Table 2 Estimation results of RMSSV models 上证综指 深证成指 沪深300 参数 均值 90%区间 均值 90%区间 均值 90%区间 p 0.995 2 [0.985 8,0.999 3] 0.995 5 [0.987 0,0.999 3] 0.996 1 [0.990 5,0.999 4] g 0.997 6 [0.993 7,0.999 6] 0.997 6 [0.994 3,0.999 6] 0.996 8 [0.992 0,0.999 5] “1 —4.018 1 [一4.133 2,一3.891 1] 一3.915 l [一4.004 5,一3.810 3] 一3.991 4 [一4.091 5,一3.888 3] P-2 —4.63l 8 [一4.721 2,一4.556 6] 一4.526 6 [一4.598 3,一4.465 0] 一4.535 8 [一4.615 3,一4.447 8] ∞ O.93l 1 [0.901 4,0.953 7] 0.919 5 [0.887 2,0.948 0] 0.928 6 [0.897 2,0.957 6] 盯" 0.097 7 [0.084 1,0.116 3] 0.108 9 [0.093 5,0.125 1] O.103 6 [0.087 5,0.122 9] 矿£ 0.364 6 [0.353 0,0.375 7] 0.360 6 [0.349 3,0.371 8] 0.365 8 [0.353 4,0.378 3] 万方数据