正在加载图片...
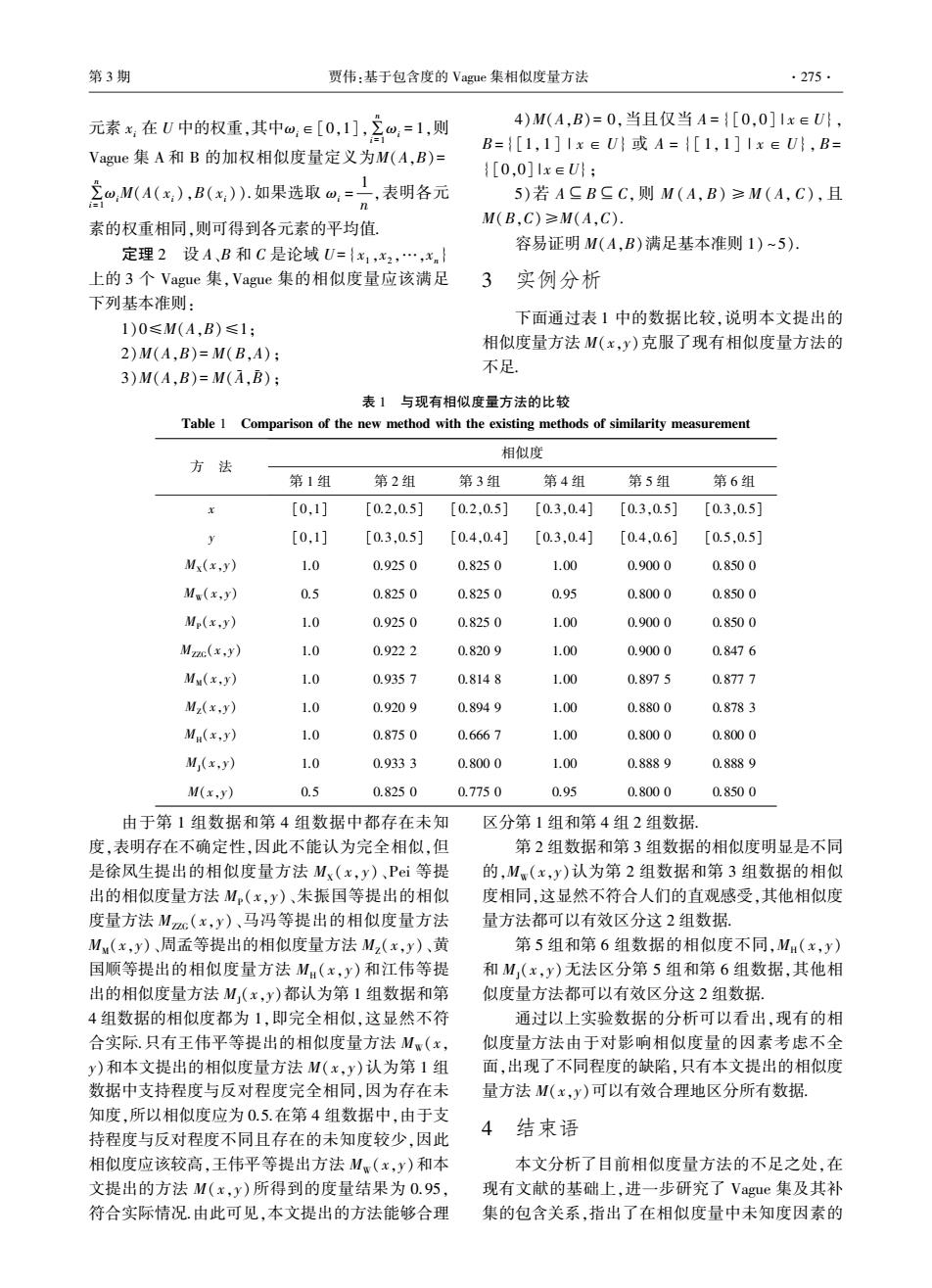
第3期 贾伟:基于包含度的Vague集相似度量方法 ·275· 元素x在U中的权重,其中0,e[0,小,三0,=1,则 4)M(A,B)=0,当且仅当A={[0,0]1x∈U}, B={[1,1]Ix∈U}或A={[1,1]Ix∈U},B= Vague集A和B的加权相似度量定义为M(A,B)= {[0,0]lx∈U}: 三,M(A(,),B(x).如果选取@,=元,表明各元 5)若A二B二C,则M(A,B)≥M(A,C),且 素的权重相同,则可得到各元素的平均值 M(B,C)≥M(A,C). 定理2设A、B和C是论域U={x1,x2,…,xn} 容易证明M(A,B)满足基本准则1)~5) 上的3个Vague集,Vague集的相似度量应该满足 3 实例分析 下列基本准则: 下面通过表1中的数据比较,说明本文提出的 1)0≤M(A,B)≤1: 2)M(A,B)=M(B,A): 相似度量方法M(x,y)克服了现有相似度量方法的 3)M(A,B)=M(A,B); 不足 表1与现有相似度量方法的比较 Table 1 Comparison of the new method with the existing methods of similarity measurement 相似度 方法 第1组 第2组 第3组 第4组 第5组 第6组 [0.1] [0.2,0.5] [0.2,0.5] [0.3,0.4] [0.3,0.5] [0.3,0.5] y [0,1] [0.3,0.5] [0.4.0.4] [0.3.0.4] [0.4.0.6] [0.5.0.5] Mx(x,y) 1.0 0.9250 0.8250 1.00 0.9000 0.8500 Mw(x.y) 0.5 0.8250 0.8250 0.95 0.8000 0.8500 Mp(x.y) 1.0 0.9250 0.8250 1.00 0.9000 0.8500 Mzc(x,y) 1.0 0.9222 0.8209 1.00 0.9000 0.8476 Mu(x.y) 1.0 0.9357 0.8148 1.00 0.8975 0.8777 Mz(x,y) 1.0 0.9209 0.8949 1.00 0.8800 0.8783 Mu(x.y) 1.0 0.8750 0.6667 1.00 0.8000 0.8000 M (x.y) 1.0 0.9333 0.8000 1.00 0.8889 0.8889 M(x,y) 0.5 0.8250 0.7750 0.95 0.8000 0.8500 由于第1组数据和第4组数据中都存在未知 区分第1组和第4组2组数据, 度,表明存在不确定性,因此不能认为完全相似,但 第2组数据和第3组数据的相似度明显是不同 是徐凤生提出的相似度量方法Mx(x,y)、Pei等提 的,M.(x,y)认为第2组数据和第3组数据的相似 出的相似度量方法M(x,y)、朱振国等提出的相似 度相同,这显然不符合人们的直观感受,其他相似度 度量方法Mc(x,y)、马冯等提出的相似度量方法 量方法都可以有效区分这2组数据.。 M(x,y)、周孟等提出的相似度量方法Mz(x,y)、黄 第5组和第6组数据的相似度不同,MH(x,y) 国顺等提出的相似度量方法M:(x,y)和江伟等提 和M,(x,y)无法区分第5组和第6组数据,其他相 出的相似度量方法M,(x,y)都认为第1组数据和第 似度量方法都可以有效区分这2组数据 4组数据的相似度都为1,即完全相似,这显然不符 通过以上实验数据的分析可以看出,现有的相 合实际.只有王伟平等提出的相似度量方法Mx(x, 似度量方法由于对影响相似度量的因素考虑不全 y)和本文提出的相似度量方法M(x,y)认为第1组 面,出现了不同程度的缺陷,只有本文提出的相似度 数据中支持程度与反对程度完全相同,因为存在未 量方法M(x,y)可以有效合理地区分所有数据, 知度,所以相似度应为0.5.在第4组数据中,由于支 持程度与反对程度不同且存在的未知度较少,因此 4结束语 相似度应该较高,王伟平等提出方法Mw(x,y)和本 本文分析了目前相似度量方法的不足之处,在 文提出的方法M(x,y)所得到的度量结果为0.95, 现有文献的基础上,进一步研究了Vague集及其补 符合实际情况.由此可见,本文提出的方法能够合理 集的包含关系,指出了在相似度量中未知度因素的元素 xi 在 U 中的权重,其中ωi∈[0,1],∑ n i = 1 ωi = 1,则 Vague 集 A 和 B 的加权相似度量定义为M(A,B)= ∑ n i = 1 ωiM(A( xi),B( xi)).如果选取 ωi = 1 n ,表明各元 素的权重相同,则可得到各元素的平均值. 定理 2 设 A、B 和 C 是论域 U= {x1 ,x2 ,…,xn } 上的 3 个 Vague 集,Vague 集的相似度量应该满足 下列基本准则: 1)0≤M(A,B)≤1; 2)M(A,B)= M(B,A); 3)M(A,B)= M(A - ,B - ); 4)M(A,B)= 0,当且仅当 A = {[0,0] | x∈U}, B = {[1,1] | x ∈ U} 或 A = {[ 1, 1] | x ∈ U}, B = {[0,0] | x∈U}; 5)若 A⊆B ⊆C,则 M ( A,B) ≥M ( A, C),且 M(B,C)≥M(A,C). 容易证明 M(A,B)满足基本准则 1) ~5). 3 实例分析 下面通过表 1 中的数据比较,说明本文提出的 相似度量方法 M(x,y)克服了现有相似度量方法的 不足. 表 1 与现有相似度量方法的比较 Table 1 Comparison of the new method with the existing methods of similarity measurement 方 法 相似度 第 1 组 第 2 组 第 3 组 第 4 组 第 5 组 第 6 组 x [0,1] [0.2,0.5] [0.2,0.5] [0.3,0.4] [0.3,0.5] [0.3,0.5] y [0,1] [0.3,0.5] [0.4,0.4] [0.3,0.4] [0.4,0.6] [0.5,0.5] MX(x,y) 1.0 0.925 0 0.825 0 1.00 0.900 0 0.850 0 MW(x,y) 0.5 0.825 0 0.825 0 0.95 0.800 0 0.850 0 MP(x,y) 1.0 0.925 0 0.825 0 1.00 0.900 0 0.850 0 MZZG(x,y) 1.0 0.922 2 0.820 9 1.00 0.900 0 0.847 6 MM(x,y) 1.0 0.935 7 0.814 8 1.00 0.897 5 0.877 7 MZ(x,y) 1.0 0.920 9 0.894 9 1.00 0.880 0 0.878 3 MH(x,y) 1.0 0.875 0 0.666 7 1.00 0.800 0 0.800 0 MJ(x,y) 1.0 0.933 3 0.800 0 1.00 0.888 9 0.888 9 M(x,y) 0.5 0.825 0 0.775 0 0.95 0.800 0 0.850 0 由于第 1 组数据和第 4 组数据中都存在未知 度,表明存在不确定性,因此不能认为完全相似,但 是徐凤生提出的相似度量方法 MX( x,y)、Pei 等提 出的相似度量方法 MP(x,y)、朱振国等提出的相似 度量方法 MZZG( x,y)、马冯等提出的相似度量方法 MM(x,y)、周孟等提出的相似度量方法 MZ(x,y)、黄 国顺等提出的相似度量方法 MH( x,y) 和江伟等提 出的相似度量方法 MJ(x,y)都认为第 1 组数据和第 4 组数据的相似度都为 1,即完全相似,这显然不符 合实际.只有王伟平等提出的相似度量方法 MW(x, y)和本文提出的相似度量方法 M(x,y)认为第 1 组 数据中支持程度与反对程度完全相同,因为存在未 知度,所以相似度应为 0.5.在第 4 组数据中,由于支 持程度与反对程度不同且存在的未知度较少,因此 相似度应该较高,王伟平等提出方法 MW(x,y)和本 文提出的方法 M( x,y)所得到的度量结果为 0.95, 符合实际情况.由此可见,本文提出的方法能够合理 区分第 1 组和第 4 组 2 组数据. 第 2 组数据和第 3 组数据的相似度明显是不同 的,MW(x,y)认为第 2 组数据和第 3 组数据的相似 度相同,这显然不符合人们的直观感受,其他相似度 量方法都可以有效区分这 2 组数据. 第 5 组和第 6 组数据的相似度不同,MH( x,y) 和 MJ(x,y)无法区分第 5 组和第 6 组数据,其他相 似度量方法都可以有效区分这 2 组数据. 通过以上实验数据的分析可以看出,现有的相 似度量方法由于对影响相似度量的因素考虑不全 面,出现了不同程度的缺陷,只有本文提出的相似度 量方法 M(x,y)可以有效合理地区分所有数据. 4 结束语 本文分析了目前相似度量方法的不足之处,在 现有文献的基础上,进一步研究了 Vague 集及其补 集的包含关系,指出了在相似度量中未知度因素的 第 3 期 贾伟:基于包含度的 Vague 集相似度量方法 ·275·