正在加载图片...
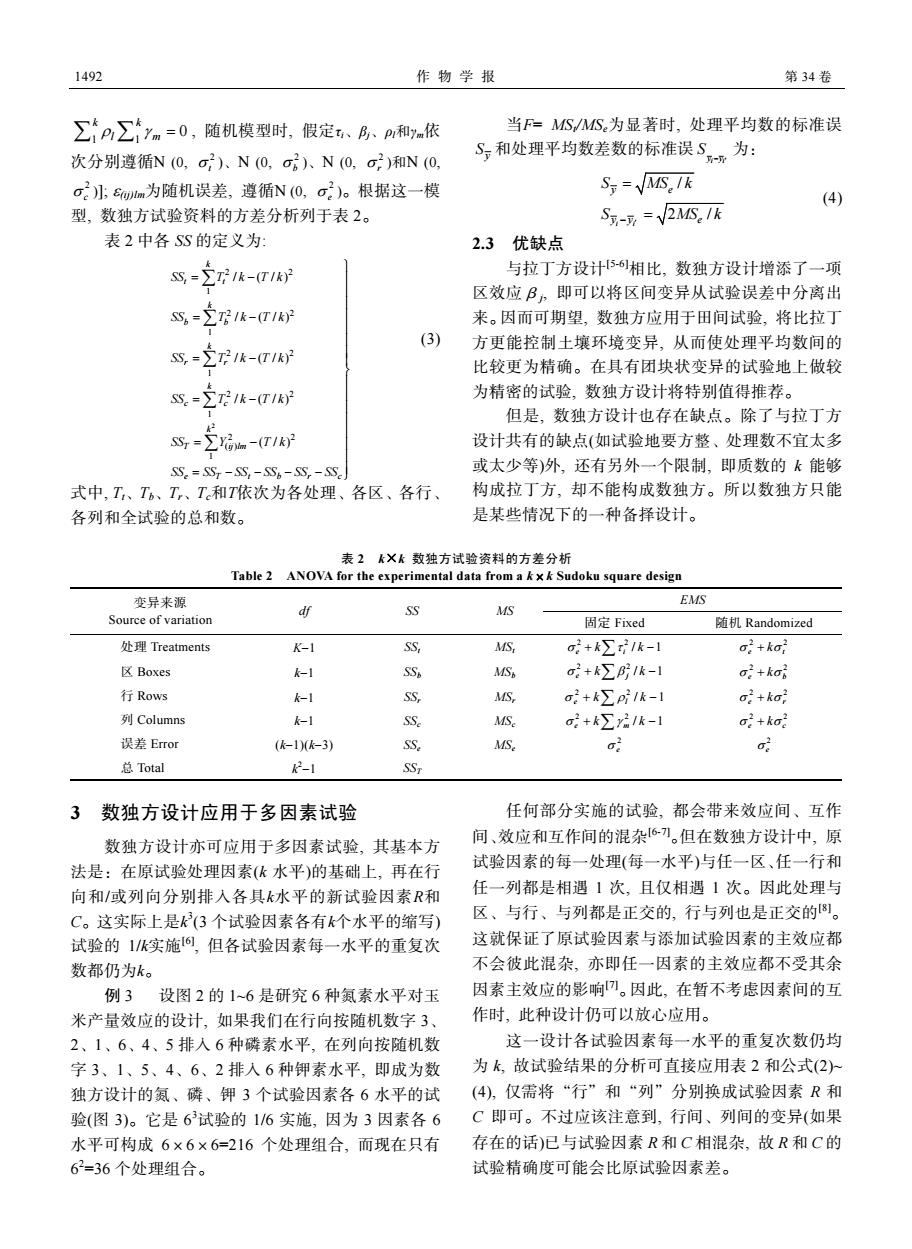
492 作物学报 第34羟 ∑∑ym=0,随机模型时,假定、B、和依 当F=MS/S为显著时,处理平均数的标准误 次分别遵循N(O,)、N(O,G、NOa)和N(O, 、和处理平均数差数的标准误S,为: o小:G为随机误差,遵循N(O,o)。根据这一模 Sy=MS,Ik 型,数独方试验资料的方差分析列于表2。 S-=2MS.1k 多 表2中各SS的定义为 2.3优缺点 8,=221k-T1 与拉丁方设计56相比,数独方设计增添了一项 区效应B。即可以将区间变异从试验误差中分离出 S,=∑1k-(T1k 来。因而可期望,数独方应用于田间试验,将比拉丁 (3) 方更能控制土壤环境变异,从而使处理平均数间的 S,=2k-T1 比较更为精确。在具有团块状变异的试验地上做较 8.=k-T1 为精密的试验,数独方设计将特别值得推荐。 但是数种方设计也存在缺占。除了与拉丁方 Ss,-Σ石h-T1k 设计共有的缺点(如试验地要方整、处理数不宜太多 或太少等)外,还有另外一个限制,即质数的k能够 、各区、各行 构成拉丁方,却不能构成数独方。所以数独方只能 各列和全试验的总和数。 是某些情况下的一种备择设计。 doku square design 变异来源 EMS oure of variation 固定Fixed 随机Randomized 处理Treatments K-1 55 S a+k∑1k-1 :+ka: 区Boxes MS, a+∑1k-l 行Row k-1 SS, a2+k∑1k-1 a2+ka 列Columns k-1 S a2+k>21k-1 o:+ka2 误差Error -1-3) s 总Total , 3数独方设计应用于多因素试验 任何部分实施的试验,都会带来效应间、互作 数独方设计亦可应用于多因素试验,其基本方 间、效应和互作间的混杂6刀。但在数独方设计中,原 法是.在原试哈处理因素(k水平)的基出上再在行 试验因素的每一处理(每一水平)与任一区、任一行和 向和/域列向分别排入各具k水平的新试验因素R利 任一列都是相遇1次,且仅相遇1次。因此处理与 C。这实际上是(3个试验因素各有k个水平的缩写) 区、与行、与列都是正交的.行与列也是正交的御 试验的1实施6,但各试验因素每一水平的重复次 这就保证了原试验因素与添加试验因素的主效应者 数都仍为k。 不会彼此混杂.亦即任一因素的主效应都不受其余 例3设图2的1~6是研究6种氨素水平对付玉 因素主效应的影响。因此,在暂不考虑因素间的互 米产量效应的设计如果我们在行向按消机数字3 作时,此种设计仍可以放心应用。 2、1、6、4、5排人6种磷素水平,在列向按随机发 这一设计各试验因素每一水平的重复次数仍的 字3、1、5、4、6、2排人6种钾素水平,即成为数 为k,故试验结果的分析可直接应用表2和公式(2) 独方设计的、磷、钾3个试哈因素各6水平的试 (4),仅需将“行”和“列”分别换成试验因素R和 验(图3)。它是6试验的16实施,因为3因素各6 C即可。不过应该注意到,行间、列间的变异(如果 水平可构成6×6×6=216个处理组合,而现在只有 存在的话)已与试验因素R和C相混杂.故R和C的 62=36个处理组合。 试验精确度可能会比原试哈因素差。1492 作 物 学 报 第 34 卷 1 1 0 k k ∑ ∑ρ γ l m = , 随机模型时, 假定τi、βj、ρl和γm依 次分别遵循N (0, 2 σ t )、N (0, 2 σ b )、N (0, 2 σ r )和N (0, 2 σ c )]; ε(ij)lm为随机误差, 遵循N (0, 2 σ e )。根据这一模 型, 数独方试验资料的方差分析列于表 2。 表 2 中各 SS 的定义为: 2 2 2 1 2 2 1 2 2 1 2 2 1 2 2 ( ) 1 / (/) / (/) / (/) / (/) (/) k t t k b b k r r k c c k T ij lm e Ttbrc SS T k T k SS T k T k SS T k T k SS T k T k SS Y T k SS SS SS SS SS SS ⎫ = − ⎪ ⎪ ⎪ = − ⎪ ⎪ ⎪ ⎪ = − ⎪ ⎬ ⎪ = − ⎪ ⎪ ⎪ ⎪ = − ⎪ ⎪ = −− −− ⎪ ⎭ ∑ ∑ ∑ ∑ ∑ (3) 式中, Tt、Tb、Tr、Tc和T依次为各处理、各区、各行、 各列和全试验的总和数。 当F= MSt/MSe为显著时, 处理平均数的标准误 y S 和处理平均数差数的标准误 y y i i S − ′ 为: / 2 / i i y e yy e S MS k S MS − ′ = = k (4) 2.3 优缺点 与拉丁方设计[5-6]相比, 数独方设计增添了一项 区效应βj, 即可以将区间变异从试验误差中分离出 来。因而可期望, 数独方应用于田间试验, 将比拉丁 方更能控制土壤环境变异, 从而使处理平均数间的 比较更为精确。在具有团块状变异的试验地上做较 为精密的试验, 数独方设计将特别值得推荐。 但是, 数独方设计也存在缺点。除了与拉丁方 设计共有的缺点(如试验地要方整、处理数不宜太多 或太少等)外, 还有另外一个限制, 即质数的 k 能够 构成拉丁方, 却不能构成数独方。所以数独方只能 是某些情况下的一种备择设计。 表 2 k×k 数独方试验资料的方差分析 Table 2 ANOVA for the experimental data from a k×k Sudoku square design 变异来源 EMS Source of variation df SS MS 固定 Fixed 随机 Randomized 处理 Treatments K−1 SSt MSt 2 2 / 1 e i σ τ + k k ∑ − 2 2 e t σ + kσ 区 Boxes k−1 SSb MSb 2 2 / 1 e j σ β + k k ∑ − 2 2 e b σ + kσ 行 Rows k−1 SSr MSr 2 2 / 1 e l σ ρ + k k ∑ − 2 2 e r σ + kσ 列 Columns k−1 SSc MSc 2 2 / 1 e m σ γ + k k ∑ − 2 2 e c σ + kσ 误差 Error (k−1)(k−3) SSe MSe 2 σ e 2 σ e 总 Total k2 −1 SST 3 数独方设计应用于多因素试验 数独方设计亦可应用于多因素试验, 其基本方 法是:在原试验处理因素(k 水平)的基础上, 再在行 向和/或列向分别排入各具k水平的新试验因素R和 C。这实际上是k3 (3 个试验因素各有k个水平的缩写) 试验的 1/k实施[6], 但各试验因素每一水平的重复次 数都仍为k。 例 3 设图 2 的 1~6 是研究 6 种氮素水平对玉 米产量效应的设计, 如果我们在行向按随机数字 3、 2、1、6、4、5 排入 6 种磷素水平, 在列向按随机数 字 3、1、5、4、6、2 排入 6 种钾素水平, 即成为数 独方设计的氮、磷、钾 3 个试验因素各 6 水平的试 验(图 3)。它是 63 试验的 1/6 实施, 因为 3 因素各 6 水平可构成 6×6×6=216 个处理组合, 而现在只有 62 =36 个处理组合。 任何部分实施的试验, 都会带来效应间、互作 间、效应和互作间的混杂[6-7]。但在数独方设计中, 原 试验因素的每一处理(每一水平)与任一区、任一行和 任一列都是相遇 1 次, 且仅相遇 1 次。因此处理与 区、与行、与列都是正交的, 行与列也是正交的[8]。 这就保证了原试验因素与添加试验因素的主效应都 不会彼此混杂, 亦即任一因素的主效应都不受其余 因素主效应的影响[7]。因此, 在暂不考虑因素间的互 作时, 此种设计仍可以放心应用。 这一设计各试验因素每一水平的重复次数仍均 为 k, 故试验结果的分析可直接应用表 2 和公式(2)~ (4), 仅需将“行”和“列”分别换成试验因素 R 和 C 即可。不过应该注意到, 行间、列间的变异(如果 存在的话)已与试验因素 R 和 C 相混杂, 故 R 和 C 的 试验精确度可能会比原试验因素差